
RNA Metabolism
S-294
1. RNA Polymerase (a) How long would it take for the E. coli RNA polymerase to synthesize the pri-
mary transcript for the E. coli genes encoding the enzymes for lactose metabolism (the 5,300 bp lac
operon, considered in Chapter 28)? (b) How far along the DNA would the transcription “bubble”
formed by RNA polymerase move in 10 seconds?
2. Error Correction by RNA Polymerases DNA polymerases are capable of editing and error correc-
tion, whereas the capacity for error correction in RNA polymerases seems to be quite limited. Given
that a single base error in either replication or transcription can lead to an error in protein synthesis,
suggest a possible biological explanation for this difference.
3. RNA Posttranscriptional Processing Predict the likely effects of a mutation in the sequence
(5⬘)AAUAAA in a eukaryotic mRNA transcript.
chapter
26
c26RNAMetabolism.qxd 12/12/12 6:44 PM Page S-294

4. Coding versus Template Strands The RNA genome of phage Qbis the nontemplate strand, or cod-
ing strand, and when introduced into the cell it functions as an mRNA. Suppose the RNA replicase of
phage Qbsynthesized primarily template-strand RNA and uniquely incorporated this, rather than
nontemplate strands, into the viral particles. What would be the fate of the template strands when
they entered a new cell? What enzyme would have to be included in the viral particles for successful
invasion of a host cell?
5. Transcription The gene encoding the E.coli enzyme b-galactosidase begins with the sequence
ATGACCATGATTACG. What is the sequence of the RNA transcript specified by this part of the gene?
6. The Chemistry of Nucleic Acid Biosynthesis Describe three properties common to the reactions
catalyzed by DNA polymerase, RNA polymerase, reverse transcriptase, and RNA replicase. How is the
enzyme polynucleotide phosphorylase similar to and different from these four enzymes?
7. RNA Splicing What is the minimum number of transesterification reactions needed to splice an in-
tron from an mRNA transcript? Explain.
8. RNA Processing If the splicing of mRNA in a vertebrate cell is blocked, the rRNA modification reac-
tions are also blocked. Suggest a reason for this.

S-296 Chapter 26 RNA Metabolism
9. RNA Genomes The RNA viruses have relatively small genomes. For example, the single-stranded
RNAs of retroviruses have about 10,000 nucleotides and the QbRNA is only 4,220 nucleotides long.
Given the properties of reverse transcriptase and RNA replicase described in this chapter, can you
suggest a reason for the small size of these viral genomes?
10. Screening RNAs by SELEX The practical limit for the number of different RNA sequences that can
be screened in a SELEX experiment is 10
15
. (a) Suppose you are working with oligonucleotides 32 nu-
cleotides long. How many sequences exist in a randomized pool containing every sequence possible?
(b) What percentage of these can be screened in a SELEX experiment? (c) Suppose you wish to se-
lect an RNA molecule that catalyzes the hydrolysis of a particular ester. From what you know about
catalysis, propose a SELEX strategy that might allow you to select the appropriate catalyst.
11. Slow Death The death cap mushroom, Amanita phalloides, contains several dangerous substances,
including the lethal a-amanitin. This toxin blocks RNA elongation in consumers of the mushroom by
binding to eukaryotic RNA polymerase II with very high affinity; it is deadly in concentrations as low
as 10
⫺8
M
. The initial reaction to ingestion of the mushroom is gastrointestinal distress (caused by
some of the other toxins). These symptoms disappear, but about 48 hours later, the mushroom-eater
dies, usually from liver dysfunction. Speculate on why it takes this long for a-amanitin to kill.
12. Detection of Rifampicin-Resistant Strains of Tuberculosis Rifampicin is an important antibiotic
used to treat tuberculosis as well as other mycobacterial diseases. Some strains of Mycobacterium tu-
berculosis, the causative agent of tuberculosis, are resistant to rifampicin. These strains become resis-
tant through mutations that alter the rpoB gene, which encodes the bsubunit of the RNA polymerase.
Rifampicin cannot bind to the mutant RNA polymerase and so is unable to block the initiation of tran-
scription. DNA sequences from a large number of rifampicin-resistant M. tuberculosis strains have
been found to have mutations in a specific 69 bp region of rpoB. One well-characterized rifampicin-
resistant strain has a single base pair alteration in rpoB that results in a His residue being replaced by
an Asp residue in the bsubunit.
(a) Based on your knowledge of protein chemistry, suggest a technique that would allow detection of
the rifampicin-resistant strain containing this particular mutant protein.
(b) Based on your knowledge of nucleic acid chemistry, suggest a technique to identify the mutant
form of rpoB.

Answer
Using the Web
13. The Ribonuclease Gene Human pancreatic ribonuclease has 128 amino acid residues.
(a) What is the minimum number of nucleotide pairs required to code for this protein?
(b) The mRNA expressed in human pancreatic cells was copied with reverse transcriptase to create
a “library” of human DNA. The sequence of the mRNA coding for human pancreatic ribonuclease
was determined by sequencing the complementary DNA (cDNA) from this library that included
an open reading frame for the protein. Use the Entrez database system
(www.ncbi.nlm.nih.gov/Entrez) to find the published sequence of this mRNA (search the nu-
cleotide database for accession number D26129). What is the length of this mRNA?
(c) How can you account for the discrepancy between the size you calculated in (a) and the actual
length of the mRNA?
Answer
Data Analysis Problem
14. A Case of RNA Editing The AMPA (␣-amino-3-hydroxy-5-methyl-4-isoxazolepropionic acid) recep-
tor is an important component of the human nervous system. It is present in several forms, in different
neurons, and some of this variety results from posttranscriptional modification. This problem explores
research on the mechanism of this RNA editing.
An initial report by Sommer and coauthors (1991) looked at the sequence encoding a key Arg
residue in the AMPA receptor. The sequence of the cDNA (see Fig. 9–14) for the AMPA receptor
showed a CGG (Arg; see Fig. 27–7) codon for this amino acid. Surprisingly, the genomic DNA showed
a CAG (Gln) codon at this position.
Chapter 26 RNA Metabolism S-297
c26RNAMetabolism.qxd 12/12/12 6:44 PM Page S-297
S-298 Chapter 26 RNA Metabolism
(a) Explain how this result is consistent with posttranscriptional modification of the AMPA receptor
mRNA.
Rueter and colleagues (1995) explored this mechanism in detail. They first developed an assay to dif-
ferentiate between edited and unedited transcripts, based on the Sanger method of DNA sequencing (see
Fig. 8–33). They modified the technique to determine whether the base in question was an A (as in CAG)
or not. They designed two DNA primers based on the genomic DNA sequence of this region of the AMPA
gene. These primers, and the genomic DNA sequence of the nontemplate strand for the relevant region of
the AMPA receptor gene, are shown below; the A residue that is edited is indicated by an asterisk.
To detect whether this A was present or had been edited to another base, Rueter and coworkers
used the following procedure:
1. Prepared cDNA complementary to the mRNA, using primer 1, reverse transcriptase, dATP, dGTP,
dCTP, and dTTP.
2. Removed the mRNA.
3. Annealed
32
P-labeled primer 2 to the cDNA, and reacted this with DNA polymerase, dGTP, dCTP,
dTTP, and ddATP (dideoxy ATP; see Fig. 8–33).
4. Denatured the resulting duplexes and separated them with polyacrylamide gel electrophoresis
(see Fig. 3–18).
5. Detected the
32
P-labeled DNA species with autoradiography.
They found that edited mRNA produced a 22 nucleotide [
32
P]DNA, whereas unedited mRNA produced
a 19 nucleotide [
32
P]DNA.
(b) Using the sequences above, explain how the edited and unedited mRNAs resulted in these differ-
ent products.
Using the same procedure, to measure the fraction of transcripts edited under different condi-
tions, the researchers found that extracts of cultured epithelial cells (a common cell line called HeLa)
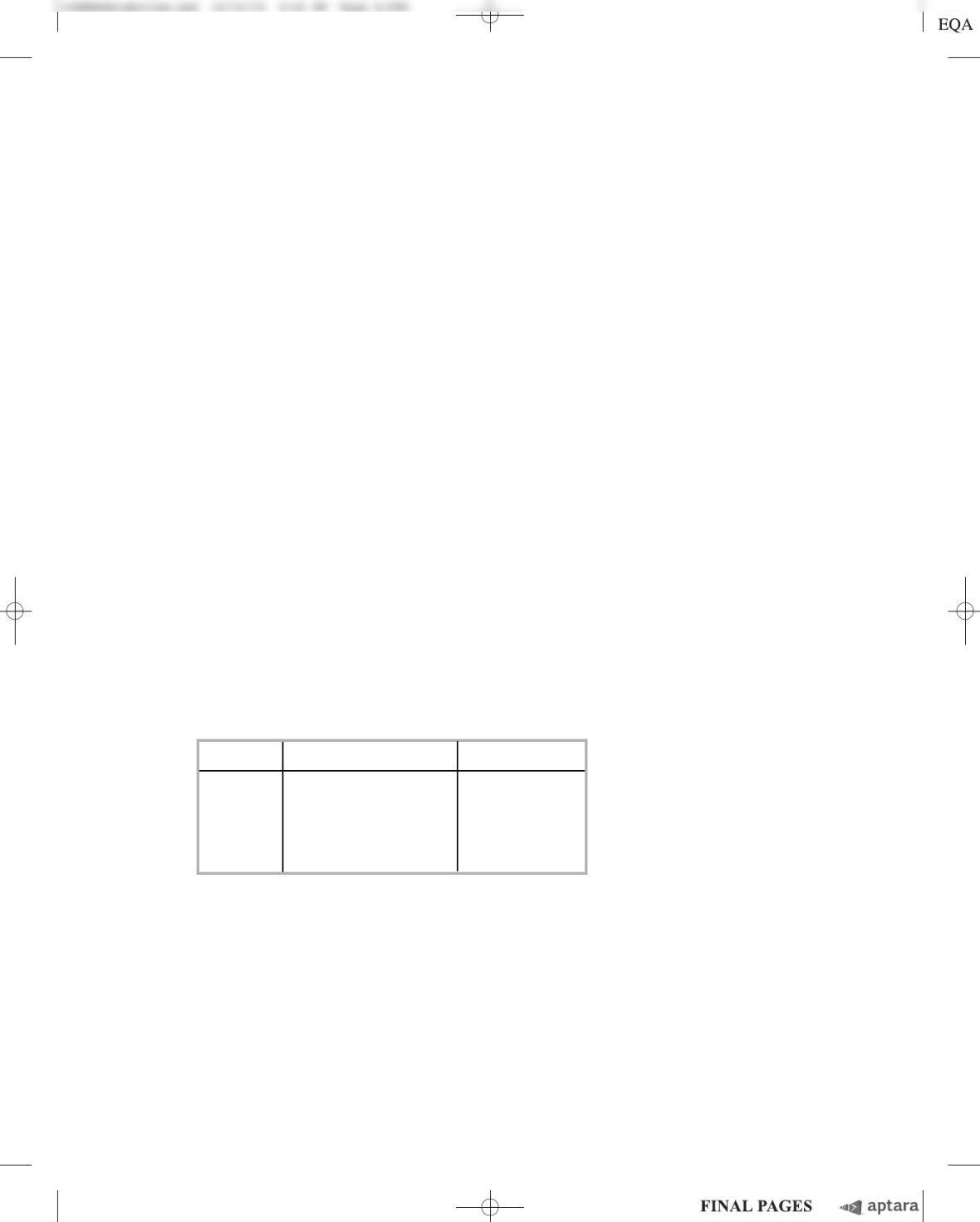
could edit the mRNA at a high level. To determine the nature of the editing machinery, they pre-
treated an active HeLa cell extract as described in the table and measured its ability to edit AMPA
mRNA. Proteinase K degrades only proteins; micrococcal nuclease, only DNA.
(5⬘) …GTCTCTGGTTTTCCTTGGGTGCCTTTATGCAGCAAGGATGCGATATTTCGCCAAG…
Primer 1: CGTTCCTACGCTATAAAGCGGTTC (5⬘)
Primer 2: (5⬘) CCTTGGGTGCCTTTA
*
Sample Pretreatment % mRNA edited
1 None 18
2 Proteinase K 5
3 Heat to 65 ⬚C3
4 Heat to 85 ⬚C3
5 Micrococcal nuclease 17
(c) Use these data to argue that the editing machinery consists of protein. What is a key weakness in
this argument?
To determine the exact nature of the edited base, Rueter and colleagues used the following proce-
dure:
1. Produced mRNA, using [␣–
32
P]ATP in the reaction mixture.
2. Edited the labeled mRNA by incubating with HeLa extract.
3. Hydrolyzed the edited mRNA to single nucleotide monophosphates with nuclease P1.
4. Separated the nucleotide monophosphates with thin-layer chromatography (TLC; see
Fig. 10–25b).
5. Identified the resulting
32
P-labeled nucleotide monophosphates with autoradiography.

In unedited mRNA, they found only [
32
P]AMP; in edited mRNA, they found mostly [
32
P]AMP with
some [
32
P]IMP (inosine monophosphate; see Fig. 22–36).
(d) Why was it necessary to use [␣–
32
P]ATP rather than [–
32
P]ATP or [␥–
32
P]ATP in this experi-
ment?
(e) Why was it necessary to use [␣–
32
P]ATP rather than [␣–
32
P]GTP, [␣–
32
P]CTP, or [␣–
32
P]UTP?
(f) How does the result exclude the possibility that the entire A nucleotide (sugar, base, and phos-
phate) was removed and replaced by an I nucleotide during the editing process?
The researchers next edited mRNA that was labeled with [2,8-
3
H]ATP, and repeated the above
procedure. The only
3
H-labeled mononucleotides produced were AMP and IMP.
(g) How does this result exclude removal of the A base (leaving the sugar-phosphate backbone in-
tact) followed by replacement with an I base as a mechanism of editing? What, then, is the most
likely mechanism of editing in this case?
(h) How does changing an A to an I residue in the mRNA explain the Gln to Arg change in protein
sequence in the two forms of AMPA receptor protein? (Hint: See Fig. 27–8).
Answer
Chapter 26 RNA Metabolism S-299
c26RNAMetabolism.qxd 12/12/12 6:44 PM Page S-299

S-300 Chapter 26 RNA Metabolism