INSTRUCTOR’S MANUAL
TO ACCOMPANY
40th Anniversary Edition
DATABASE PROCESSING
Fundamentals, Design, and Implementation
15th Edition
Chapter 8
Database Redesign
David M. Kroenke | David J. Auer | Scott L. Vandenberg | Robert C. Yoder

Chapter 8 – Database Redesign
Page 8-2
❖ CHAPTER OBJECTIVES
• To understand the need for database redesign
• To be able to use correlated subqueries
• To be able to use the SQL EXISTS and NOT EXISTS comparison operators
in correlated subqueries
❖ ERRATA
Page 451, StoreID should start at 1000, not 100.
❖ TEACHING SUGGESTIONS
• Stress to your students, who may have no experience working with databases in the
“real world,” that database redesign is a very common occurrence. Many databases,
particularly in companies without good database development staffs, are improperly
designed, and it will not be unusual for your students to encounter such databases.
Even if the company has properly developed databases, the continuing evolution of
the company and how it functions will create the need for database redesign.

Chapter 8 – Database Redesign
Page 8-3
• Spend some time with EXISTS and NOT EXISTS, and how their use in a query
creates a correlated subquery. Take the time to thoroughly examine the classic
double NOT EXISTS pattern on pages 429–431.
NOTE: The solutions for Chapter 8 are shown for SQL Server 2017 only.
Solutions for Microsoft Access 2016, Oracle Database, and MySQL 5.7
will be similar, but may require some minor modifications because of
SQL syntax variations.

Chapter 8 – Database Redesign
Page 8-4
❖ ANSWERS TO REVIEW QUESTIONS
8.1 Review the three sources of database design and implementation.
Databases are created (1) from existing data, (2) from the development of new information
8.2 Describe why database redesign is necessary.
Database design involves taking a set of requirements and creating from scratch a database
8.3 Explain the following statement in your own words: “Information systems and
organizations create each other.” How does this relate to database redesign?
When a new information system is installed, the users can behave in new ways. As the users
8.4 Suppose that a table contains two nonkey columns: AdvisorName and AdvisorPhone.
Further suppose that you suspect that AdvisorPhone
→
AdvisorName. Explain how to
examine the data to determine if this supposition is true.
Check the table to determine if each AdvisorPhone has only one value of AdvisorName. If the
Chapter 8 – Database Redesign
Page 8-5
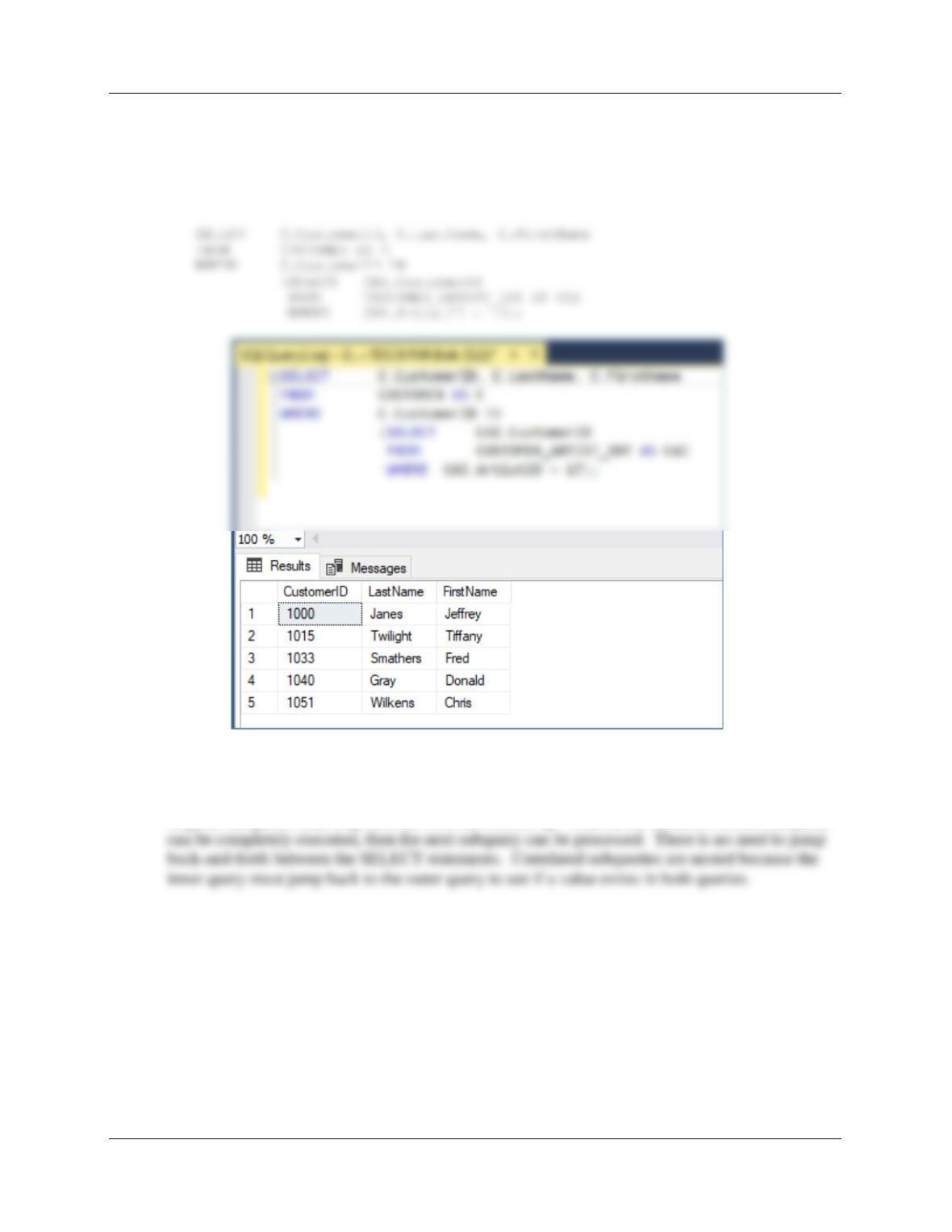
8.5 Write a subquery, other than one in this chapter, that is not a correlated subquery.
We’ll use the View Ridge Gallery database data from Chapter 7 for this example.
For SQL Server:
8.6 Explain the following statement: “The processing of correlated subqueries is nested,
whereas that of regular subqueries is not.”
Regular subqueries can be processed from the bottom up. That is, the bottom or inside subquery
Page 8-6
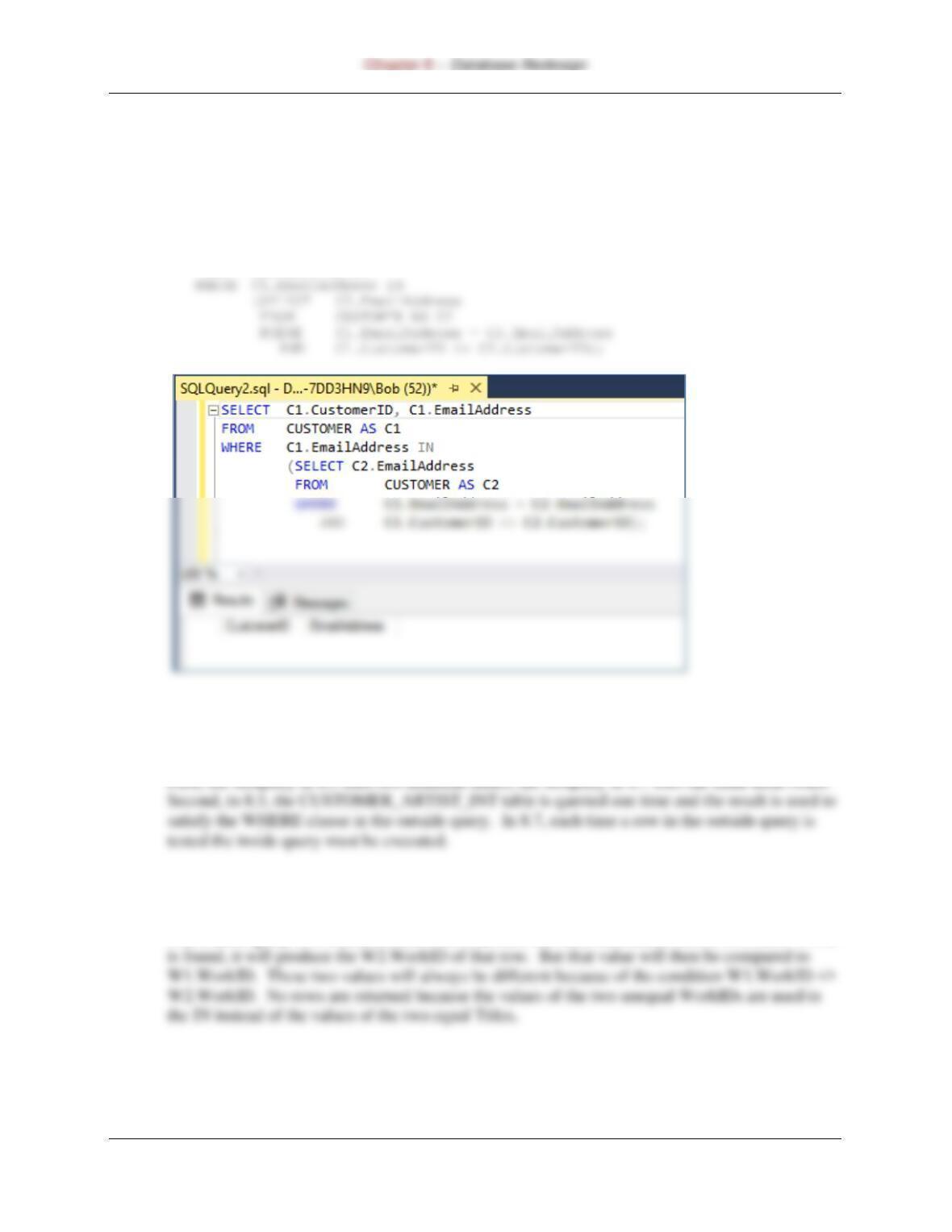
8.7 Write a correlated subquery, other than one in this chapter.
We’ll check the values in CUSTOMER.Email to see if it could be used as a primary key. It was
defined as UNIQUE and therefore as an alternate key. The result should be, and is, an empty set.
For SQL Server:
SELECT C1.CustomerID, C1.EmailAddress
FROM CUSTOMER AS C1
8.8 Explain how the query in your answer to Review Question 8.5 differs from the query in
your answer to Review Question 8.7.
8.9 Explain what is wrong with the correlated subquery SQL-Query-CH08-03 on page 428.
The bottom query will indeed find all rows that have the same title and different WorkIDs. If one

Chapter 8 – Database Redesign
Page 8-7
8.10 Write a correlated subquery to determine whether the data support the supposition in
question 8.4.
SELECT A1.AdvisorName, A1.AdvisorPhone
FROM ADVISOR A1
8.11 Explain the meaning of the SQL EXISTS comparison operator.
8.12 Answer Review Question 8.10, but use the SQL EXISTS comparison operator.
SELECT A1.AdvisorName, A1.AdvisorPhone
8.13 Explain how any and all pertain to EXISTS and NOT EXISTS.
The EXISTS keyword will be true if any row in the subquery meets the condition. The NOT
8.14 Explain the processing of SQL-Query-CH08-06 on page 430.
Find Artists that Every Customer is interested in:
For each Artist, Scan through all of the Customers.
Print the Artists that have NO Customers that DO NOT have a Customer-Interest entry for
that Artist.
The bottom SELECT finds all of the customers that are interested in a particular artist. The NOT
EXISTS in the sixth line of the query will find the customers who are not interested in the given
Chapter 8 – Database Redesign
Page 8-8
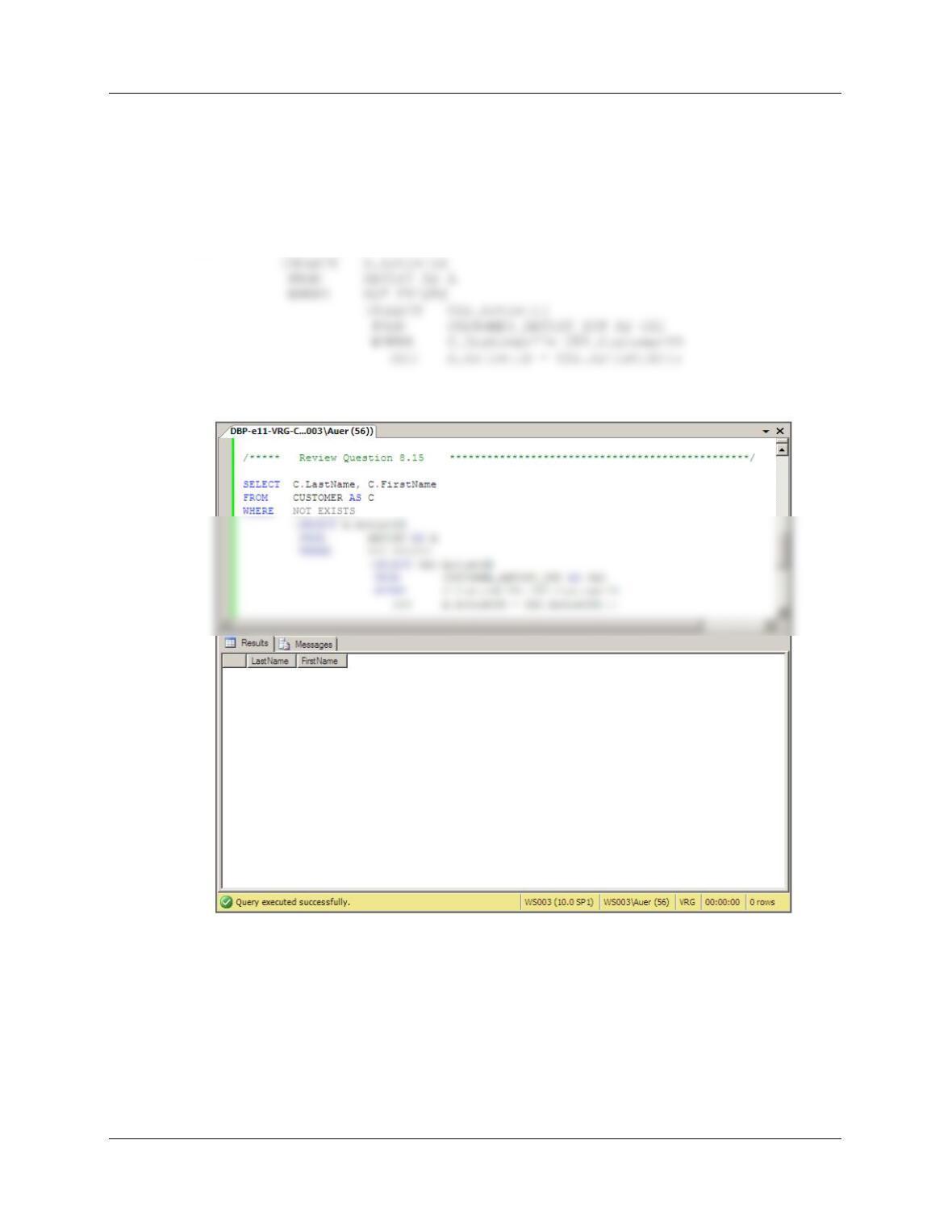
8.15 Using the View Ridge Gallery database, write a query that will display the names of any
customers who are interested in all artists.
SELECT C.LastName, C.FirstName
FROM CUSTOMER AS C
WHERE NOT EXISTS
As shown in the screen shot, there are none.

Chapter 8 – Database Redesign
Page 8-9
8.16 Explain how the query in your answer to question 8.15 works.
Find Artists that Every Customer is interested in:
For each Artist, Scan through all of the Customers.
Print the Artists that have NO Customers that DO NOT have a Customer-Interest entry for
that Artist.
8.17 Why is it important to analyze the database before implementing database redesign
tasks? What can happen if this is not done?
You must analyze the database because you must know the impact of any changes you may
8.18 Explain the process of reverse engineering.
8.19 Why is it important to carefully evaluate the results of reverse engineering?
It is important to carefully evaluate the results of reverse engineering because the model produced
8.20 What is a dependency graph? What purpose does it serve?
Dependency graphs are not graphical displays like bar charts, but rather they are diagrams that
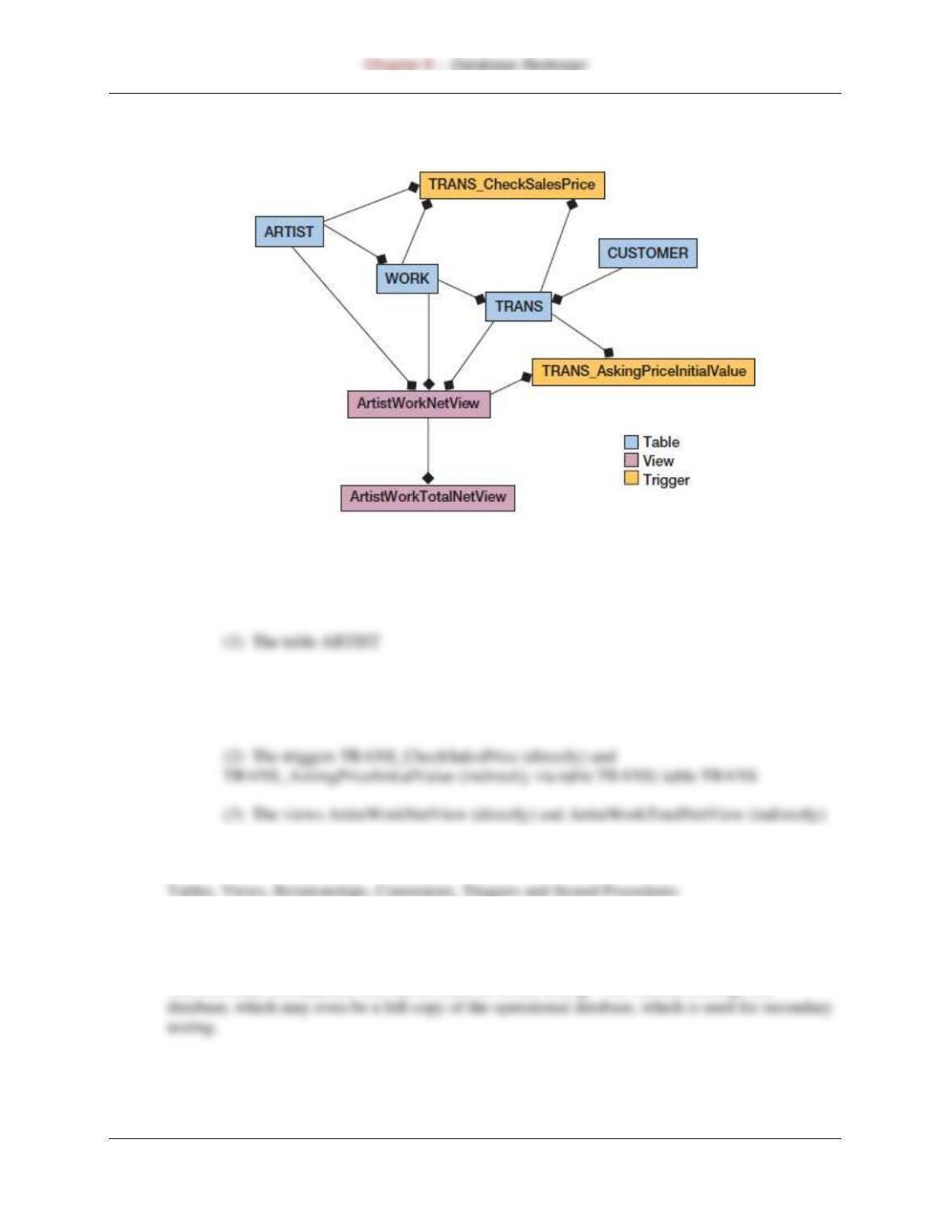
Page 8-10
8.21 Explain the dependencies for WORK in the graph in Figure 8-4.
Figure 8-4 – Example Dependency Graph (Partial)
WORK itself is dependent upon:
The following database constructs are dependent on WORK:
(1) The table TRANS
8.22 What sources are used when creating a dependency graph?
8.23 Explain two different types of test databases that should be used when testing database
redesign changes.
One is a small test database that can be used for initial testing. The second is a large test

Chapter 8 – Database Redesign
8.24 Explain the problems that can occur when changing the name of a table.
Constraints that define the relationships must be altered, views must be redefined and triggers
must be rewritten to use the new name.
8.25 Describe the process of changing a table name.
(1) Create a new table with the new name. (do not define old surrogate keys as such if there are
FK rows in another table that refer to them).
(2) Alter any constraints, triggers, or views that may be affected.
8.26 Considering Figure 8-4, describe the tasks that need to be accomplished to change the
name of the table WORK to WORK_VERSION2.
(1) Create the table by submitting a CREATE TABLE WORK_VERSION2 statement to the
(3) Redefine the view ArtistWorkNetView.
(4) Rewrite the TRANS_CheckSalesPrice trigger.
8.27 Explain how views can simplify the process of changing a table name.
If an application uses program logic that always references views, then the only application

Chapter 8 – Database Redesign
8.28 Under what conditions is the following SQL statement valid?
INSERT INTO T1 (A, B)
SELECT (C, D) FROM T2;
8.29 Show an SQL statement to add an integer column C1 to the table T2. Assume that C1 is
NULL.
ALTER TABLE T2
ADD COLUMN C1 Int NULL;
8.30 Extend your answer to Review Question 8.29 to add C1 when C1 is to be NOT NULL.
8.31 Show an SQL statement to drop the column C1 from table T2.
8.32 Describe the process for dropping primary key C1 and making the new primary key C2.
(1) Drop any foreign key constraints that reference the C1 primary key.
8.33 Which data type changes are the least risky?
Generally, converting numeric to char or varchar is not risky. Converting date or money or other
more specific data type to char or varchar will usually succeed.
8.34 Which data type changes are the most risky?
8.35 Show an SQL statement to change a column C1 to Char(10) NOT NULL. What
conditions must exist in the data for this change to be successful?

Chapter 8 – Database Redesign
8.36 Explain how to change the minimum cardinality when a child that was required to have a
parent is no longer required to have one.
First, drop the foreign key constraint. Second, alter the column definition for the column that is
8.37 Explain how to change the minimum cardinality when a child that was not required to
have a parent is now required to have one. What condition must exist in the data for this
change to work?
8.38 Explain how to change the minimum cardinality when a parent that was required to have
a child is no longer required to have one.
8.39 Explain how to change the minimum cardinality when a parent that was not required to
have a child is now required to have one.
8.40 Describe how to change the maximum cardinality from 1:1 to 1:N. Assume that the
foreign key is on the side of the new child in the 1:N relationship.
8.41 Describe how to change the maximum cardinality from 1:1 to 1:N. Assume that the
foreign key is on the side of the new parent in the 1:N relationship.
(1) Add a column to the table that is the many side of the relationship. This column will be the
foreign key that references the parent table. This foreign key is not unique.
(2) Write an UPDATE command to place the value of the primary key in the new foreign key.

Chapter 8 – Database Redesign
Page 8-14
8.42 Assume that tables T1 and T2 have a 1:1 relationship. Assume that T2 has the foreign
key. Show the SQL statements necessary to move the foreign key to T1. Make up your
own names for primary and foreign keys.
NOTE: PK = Primary Key; FK = Foreign Key
ALTER TABLE T1
ADD COLUMN FK1 Int NULL UNIQUE;
8.43 Explain how to transform a 1:N relationship into an N:M relationship.
(1) Create the intersection table. Foreign key constraints can be done while creating the table or
as a separate step.
8.44 Suppose that tables T1 and T2 have a 1:N relationship. Show the SQL statements
necessary to fill an intersection T1_T2_INT. Make up your own names for primary and
foreign keys.
NOTE: PK = Primary Key; FK = Foreign Key
8.45 Explain how the reduction of maximum cardinalities causes data loss.
Anytime you reduce maximum cardinalities you will lose instances of relationships. This causes

Chapter 8 – Database Redesign
Page 8-15
8.46 Using the tables in your answer to Review Question 8.44, show the SQL statements
necessary to change the relationship back to 1:N. Assume that the first row in the
qualifying rows of the intersection table is to provide the foreign key. Use the keys and
foreign keys from your answer to Review Question 8.44.
NOTE: PK = Primary Key; FK = Foreign Key
ALTER TABLE T2
ADD COLUMN FK2 Int NULL;
8.47 Using the results of your answer to Review Question 8.46, explain what must be done to
convert this relationship to 1:1. Use the keys and foreign keys from your answer to
question 8.46.
(1) Make sure that the value of a foreign key does not exist more than once in table T2.
8.48 In general terms, what must be done to add a new relationship?
To add a relationship, simply create a foreign key constraint. You will probably need to add a
8.49 Suppose that tables T1 and T2 have a 1:N relationship, with T2 as the child. Show the
SQL statements necessary to remove table T1. Make your own assumptions about the
names of keys and foreign keys.
ALTER TABLE T2
DROP CONSTRAINT FK2;

8.50 What are the risks and problems of forward engineering?
Much depends on the nature of the changes to be made and the quality of the forward engineering
❖ ANSWERS TO PROJECT QUESTIONS
8.51 Suppose that the table EMPLOYEE has a 1:N relationship to the table
PHONE_NUMBER. Further suppose that the primary key of EMPLOYEE is EmployeeID
and the columns of PHONE_NUMBER are PhoneNumberID (a surrogate key),
AreaCode, LocalNumber, and EmployeeID (a foreign key to EMPLOYEE). Alter this
design so that EMPLOYEE has a 1:1 relationship to PHONE_NUMBER. For employees
having more than one phone number, keep only the first one.
To start with, let’s write out the table structure:
EMPLOYEE (EmployeeID, {Other Attributes})
8.52 Suppose that the table EMPLOYEE has a 1:N relationship to the table
PHONE_NUMBER. Further suppose that the key of EMPLOYEE is EmployeeID and the
columns of PHONE_NUMBER are PhoneNumberID (a surrogate key), AreaCode,
LocalNumber, and EmployeeID (a foreign key to EMPLOYEE). Code all SQL
statements necessary to redesign this database so that it has just one table. Explain the
difference between the result of question 8.51 and the result of this question.
To start with, let’s write out the table structure:
Now we:
(1) Add the columns AreaCode and LocalNumber to EMPLOYEE.

Chapter 8 – Database Redesign
SQL: We will assume that:
(1) PHONE_NUMBER.AreaCode is Char(3)
ALTER TABLE EMPLOYEE
ADD COLUMN AreaCode Char(3)NULL;
ALTER TABLE EMPLOYEE
ADD COLUMN LocalNumber Char(8)NULL;
At this point we would make EMPLOYEE.AreaCode and EMPLOYEE.LocalNumber NOT
NULL if each EMPLOYEE had a phone number and NOT NULL was the necessary condition
for these columns.
The difference is that in question 8.51 we end up with two tables EMPLOYEE and
PHONE_NUMBER in a 1:1 relationship. In this question, we end up with only one table and
thus no relationship.
8.53 Consider the following table:
TASK (EmployeeID, EmpLastName, EmpFirstName, Phone, OfficeNumber,
ProjectName, Sponsor, WorkDate, HoursWorked)

Chapter 8 – Database Redesign
A. Write SQL statements to display the values of any rows that violate these
functional dependencies.
SELECT T1.EmployeeID, T1.EmpLastName, T1.EmpFirstName,
T1.Phone, T1.OfficeNumber
FROM TASK AS T1
WHERE T1.EmployeeID IN
(SELECT T2.EmployeeID
FROM TASK AS T2
WHERE (T1.EmployeeID = T2.EmployeeID
AND T1.Name <> T2.Name)
B. If no data violate these functional dependencies, can we assume that they are
valid? Why or why not?
You cannot assume that the functional dependencies are correct. You can only assume
C. Assume that these functional dependencies are true and that the data have been
corrected, as necessary, to reflect them. Code all SQL statements necessary to
redesign this table into a set of tables in BCNF and 4NF. Assume that the table
does have data values that must be appropriately transformed to the new design.
CREATE TABLE EMPLOYEE(
EmployeeID Int NOT NULL,
NOTE: We will assume that:
(1) If an EMPLOYEE is deleted, we want to delete all associated TASK records.

Chapter 8 – Database Redesign
Page 8-19
(3) Primary key updates in EMPLOYEE and PROJECT should always be updated in
TASK.
CREATE TABLE TASK(
EmployeeID Int NOT NULL,
ProjectName Char(20) NOT NULL,
WorkDate DateTime NOT NULL,
❖ MARCIA’S DRY CLEANING CASE QUESTIONS
Marcia Wilson owns and operates Marcia’s Dry Cleaning, which is an upscale dry cleaner in a
well-to-do suburban neighborhood. Marcia makes her business stand out from the competition
by providing superior customer service. She wants to keep track of each of her customers and
their orders. Ultimately, she wants to notify them that their clothes are ready via e-mail. Suppose
that you have designed a database for Marcia’s Dry Cleaning that has the following tables:
Assume that all relationships have been defined, as implied by the foreign keys in this table list, and that
the appropriate referential integrity constraints are in place. The referential integrity constraints are:
CustomerID in INVOICE must exist in CustomerID in CUSTOMER
Assume that CustomerID of CUSTOMER, EmployeeID of EMPLOYEE, ItemID of ITEM,
SaleID of SALE, and SaleItemID of SALE_ITEM are all surrogate keys with values as follows:
CustomerID Start at 100 Increment by 1
Chapter 8 – Database Redesign
Page 8-20
If you want to run these solutions in a DBMS product, first create a version of the MDC
database described in the Case Problems in Chapter 10A for SQL Server 2017, Chapter 10B
for Oracle Database, and Chapter 10C for MySQL 5.7. Name the database MDC-CH08.
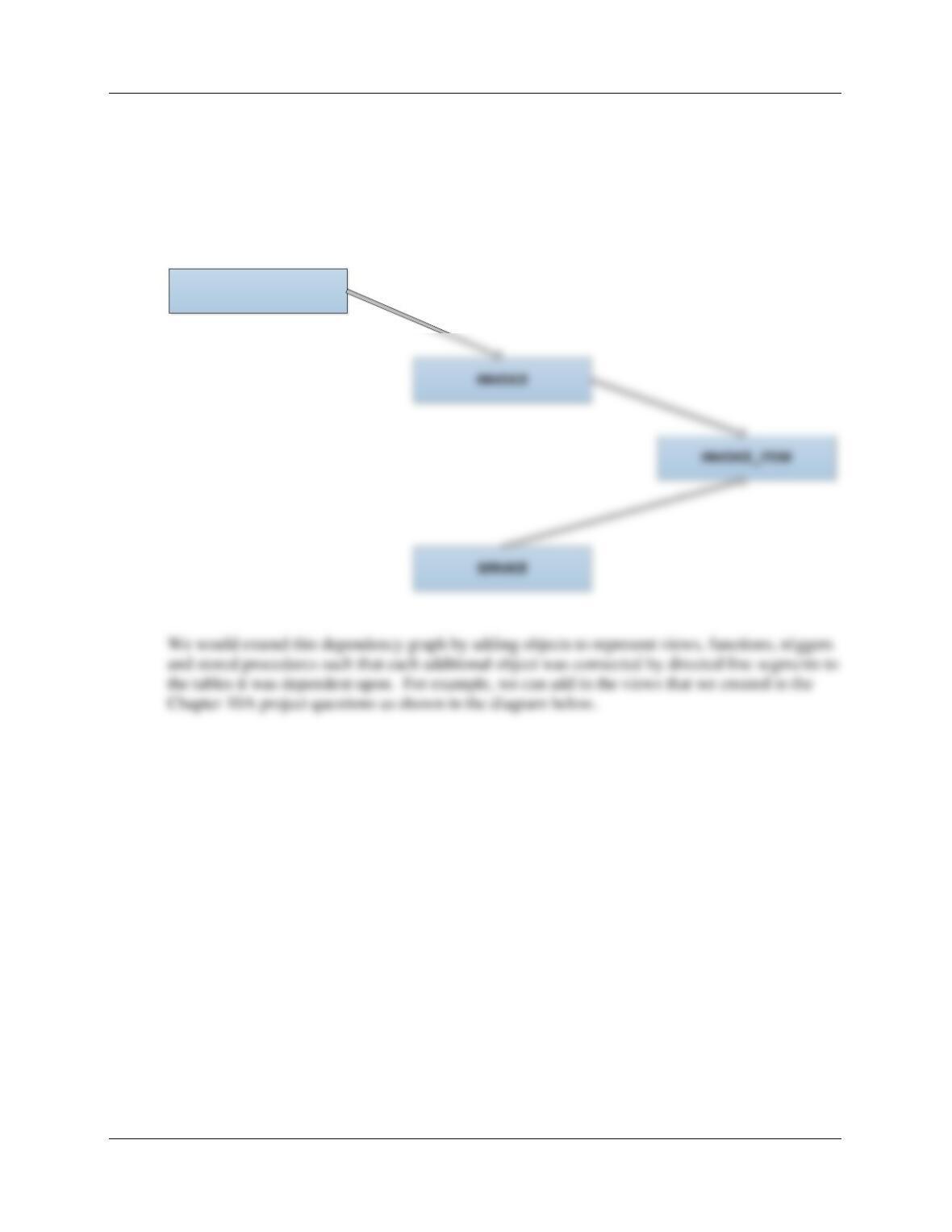
A. Create a dependency graph that shows dependencies among these tables. Explain how
you need to extend this graph for views and other database constructs such as triggers and
stored procedures.
CUSTOMER