INSTRUCTOR’S MANUAL
TO ACCOMPANY
40th Anniversary Edition
DATABASE PROCESSING
Fundamentals, Design, and Implementation
15th Edition
Chapter 12
Data Warehouses, Business Intelligence Systems, and
Big Data
David M. Kroenke | David J. Auer | Scott L. Vandenberg | Robert C. Yoder

Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
Page 12-2
❖ CHAPTER OBJECTIVES
• To learn the basic concepts of data warehouses and data marts
• To learn the basic concepts of dimensional databases
• To understand the nature and scope of business intelligence (BI) systems
❖ ERRATA
There are no known errors at this time. Any errors that are discovered in the future will
❖ TEACHING SUGGESTIONS
• Explain to your students that business intelligence (BI) systems already have an
important role in business operations, and the importance of this role should only
increase over time. If you know of any local examples, use them to illustrate your
point.

Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
Page 12-3
• The RFM portions of this chapter illustrate that some very useable BI applications
can be built using only SQL.
• It is difficult to gain hand-on experience in many data mining techniques without
more advanced courses in programming or statistics. However, some DBMS
products now come bundled with GUI interfaces that make it easier to learn the
basics. In addition, Market Basket Analysis can be done to some extent in SQL;
see Appendix J for more.
• Oracle and Postgres are two DBMS products that provide built-in object-
relational features; there are many examples on the Internet that could be used
to illustrate this for students.
❖ ANSWERS TO REVIEW QUESTIONS
12.1 What are BI systems?
Business Information (BI) systems are information systems that assist managers and other
12.2 How do BI systems differ from transaction processing systems?
BI systems differ from transaction processing systems in that they do not support normal
12.3 Name and describe the two main categories of BI systems.

Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
12.4 What are the three sources of data for BI systems?
BI systems obtain data in three ways:
(1) Data from operational databases – BI systems read and process operational
DBMS data, but do not insert, modify, or delete the data.
12.5 Explain the difference in processing between reporting and data mining applications.
Reporting systems summarize the current status of the business and compare it to current or
12.6 Describe three reasons why direct reading of operational data is not feasible for BI
applications.
(1) BI queries can substantially burden the operational DBMS and slow the operational
12.7 Summarize the problems with operational databases that limit their usefulness for BI
applications.
The problems that inhibit the usefulness of operational databases for BI applications are:
(1) Dirty data
12.8 What are dirty data? How do dirty data arise?

Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
Dirty data are problematic data, that is, data that has been recorded with improper values. An
12.9 Why is server time not useful for Web-based order entry BI applications?
Server time is an example of inconsistent data. For example, an on-line customer is concerned
12.10 What is click-stream data? How is it used in BI applications?
Click-stream data is a recording of every action a customer takes (as indicated by clicking the
12.11 Why are data warehouses necessary?
12.12 Why do the authors describe the data in Figure 12-6 as “frightening?”
12.13 Give examples of data warehouse metadata.
Data warehouse metadata includes data source, data format, data assumptions, and constraints.
12.14 Explain the difference between a data warehouse and a data mart. Use the analogy of a
supply chain.
A data warehouse stores data that reflect the entire business, whereas a data mart stores data that
Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
Page 12-6
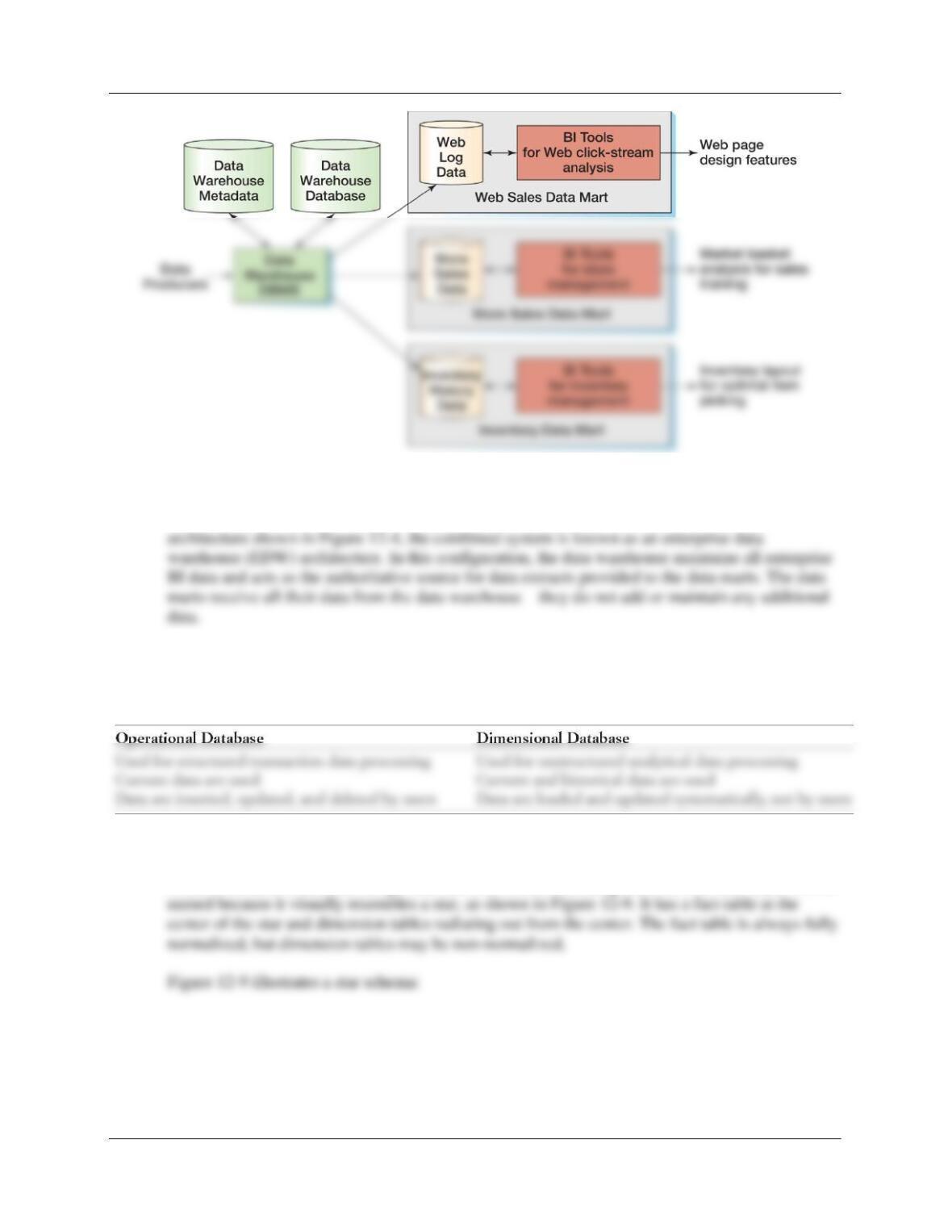
12.15 What is the enterprise data warehouse (EDW) architecture?
When the data mart structure shown in Figure 12-7 is combined with the data warehouse
12.16 Describe the differences between operational databases and dimensional databases.
The differences as summarized in Figure 12-8:
12.17 What is a star schema?
A star schema is a database design that uses a denormalized design to store historical data. It is so

Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
Page 12-7
12.18 What is a fact table? What type of data is stored in fact tables?
A fact table is a table in a dimensional database that is used to store measures of business activity,
12.19 What is a measure?
12.20 What is a dimension table? What type of data is stored in dimension tables?
12.21 What is a slowly changing dimension?
A slowly changing dimension is a column of historical data that changes over time.
12.22 Why is the time dimension important in a dimensional model?
Because dimensional databases are used for the analysis of historical data, they must be designed
12.23 What is a conformed dimension?
A conformed dimension is a dimension table that is used in more than one star schema to
12.24 State the purpose of a reporting system.

Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
12.25 What do the letters RFM stand for in RFM analysis?
R = Recent – when was the customer’s most recent purchase
12.26 Describe in general terms how to perform an RFM Analysis.
To perform an RFM analysis:
(1) Sort the customer purchase records (CPRs) on the R basis into five groups, where each
(2) Re-sort the customer purchase records (CPRs) on the F basis into five groups, where each
group contains 20% of the CPRs. The ranked CPRs are each assigned an F score as
follows:
1 = top 20% (most frequently)
2 = next 20%
3 = next 20%
4 = next 20%
5 = bottom 20% (least frequently)
Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
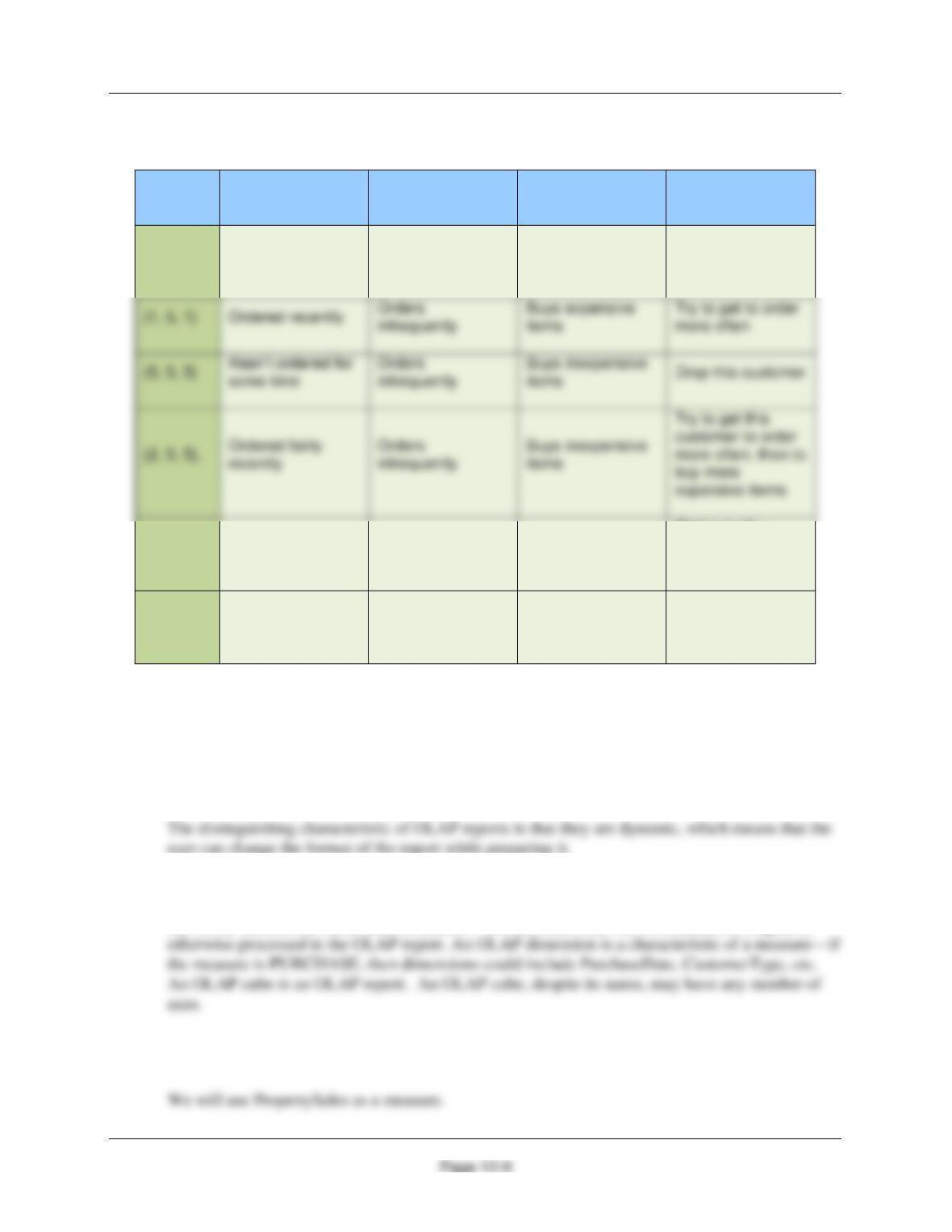
12.27 Explain the characteristics of customers that have the following RFM scores: {1 1 5},
{1 5 1}, {5 5 5}, {2 5 5}, {5 1 2}, {1 1 3}.
RFM
SCORE
R
F
M
Comments
{1, 1, 5}
Ordered recently
Orders frequently
Buys inexpensive
items
Try to move to
more expensive
items
{1, 5, 1}
Ordered recently
Orders
infrequently
Buys expensive
items
Try to get to order
more often
{2, 5, 5},
more often, then to
buy more
expensive items
{5, 1, 2}
Hasn’t ordered for
some time
Orders frequently
Buys somewhat
expensive items
Find out why
customer hasn’t
ordered recently
{1, 1, 3}
Ordered recently
Orders frequently
Buys moderately
priced items
Try to move to
more expensive
items
12.28 What does OLAP stand for?
OLAP stands for online Analytical Processing.
12.29 What is the distinguishing characteristic of OLAP reports?
12.30 Define measure, dimension, and cube.
An OLAP measure is a data item of interest—it is the items that will be summed, averaged, or
12.31 Give an example, other than one in this text, of a measure, two dimensions related to
your measure, and a cube.
Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
Page 12-10
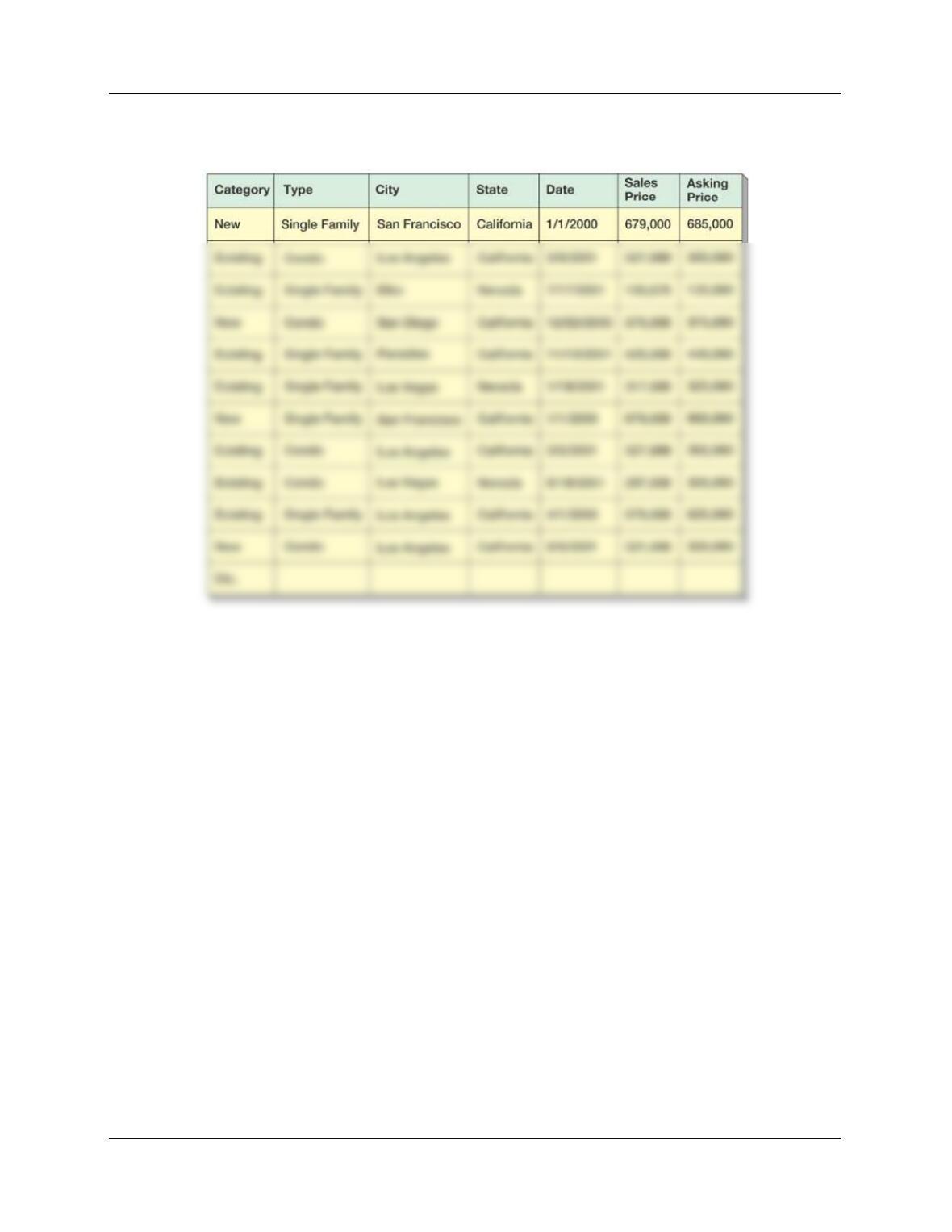
Dimensions would be the attributes in a relational database table, such as Category, Type, etc.
Data as stored in a relational database table would be shown as:
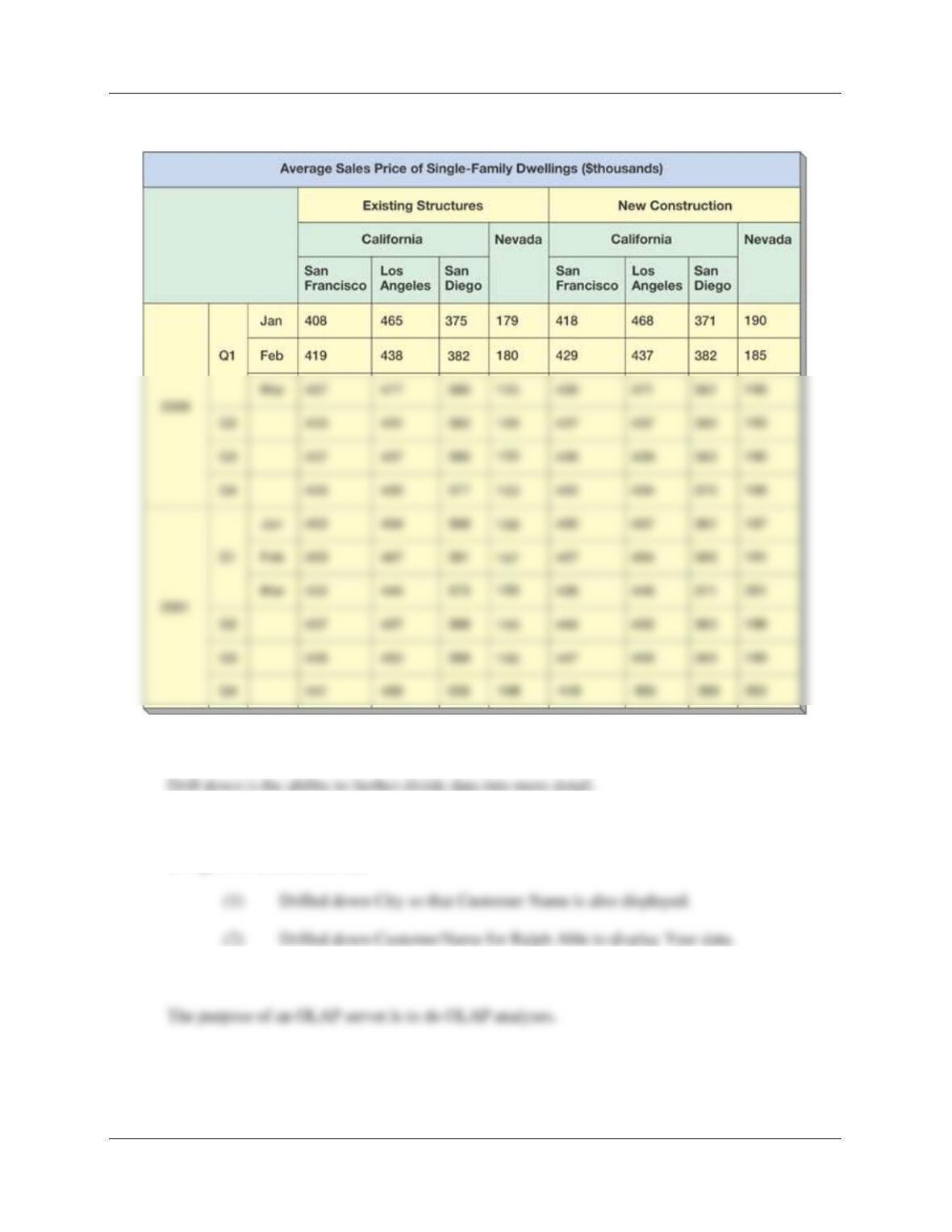
Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
Page 12-11
Here is an example cube:
12.32 What is drill down?
12.33 Explain how the OLAP report in Figure 12-23 differs from that in Figure 12-22.
In Figure 12-22, the user has:
12.34 What is the purpose of an OLAP server?

Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
Page 12-12
12.35 Define distributed database.
A distributed database is a database that:
(1) Has been split into sections called partitions, and has the partitions stored on different
12.36 Explain one way to partition a database that has three tables: T1, T2, and T3.
Assume we have three database servers—S1, S2, and S3. Partition the database by putting one
12.37 Explain one way to replicate a database that has three tables: T1, T2, and T3.
Assume we have three database servers—S1, S2, and S3. Replicate the database by putting all
12.38 Explain what must be done when fully replicating a database but allowing only one
computer to process updates.
If only one computer accepts updates, the copies of the updates must be periodically sent to the
12.39 If more than one computer can update a replicated database, what three problems can
occur?
If more than one computer can update a replicated database, then:
12.40 What solution is used to prevent the problems in Review Question 12.39?
12.41 Explain what problems can occur in a distributed database that is partitioned but not
replicated.
If a distributed database is partitioned by not replicated, then problems will occur only if a

Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
Page 12-13
12.42 What organizations should consider using a distributed database?
Replicated, read-only databases present few problems, but distributed databases should only be
12.43 Explain the meaning of the term object persistence.
Object persistence means storing the values of the properties of an object.
12.44 In general terms, explain why relational databases are difficult to use for object
persistence.
12.45 What does OODBMS stand for, and what is its purpose?
12.46 According to this chapter, why were OODBMSs not successful?
OODBMSs were not successful because by the time they were introduced too much data was
12.47 What is an object-relational database?
An object-relational database is a relational database that has the full functionality of a relational
12.48 What is virtualization?
Virtualization is the sharing of hardware resources with more than one computer. One physical
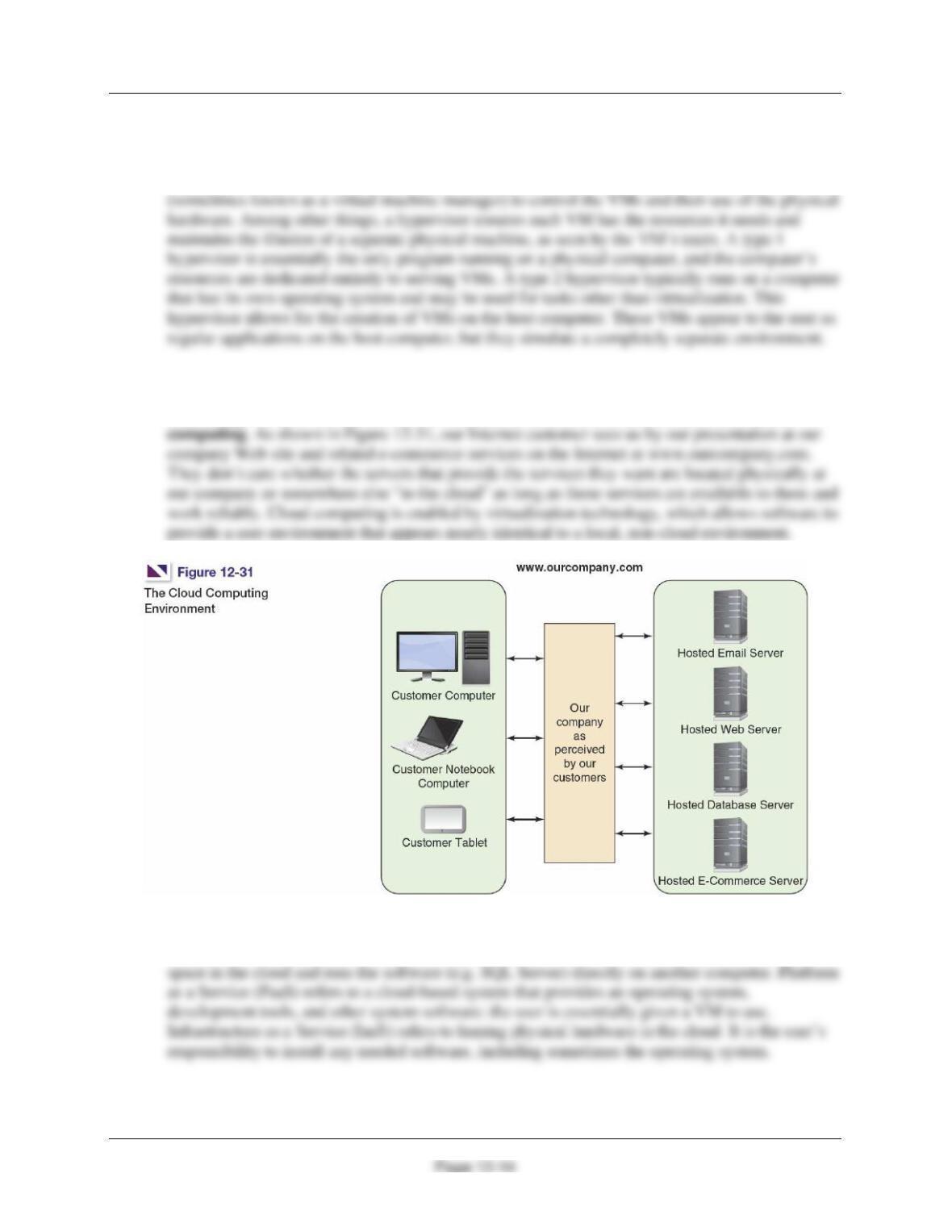
Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
12.49 What is a hypervisor, and what is the difference between a type 1 hypervisor and a type
2 hypervisor?
A physical computer hosting one or more virtual machines runs a program called a hypervisor
12.50 What is cloud computing? What major technology enables cloud computing?
The configuration of servers and services hosted for us over the Internet is known as cloud
12.51 What are the differences between SaaS, PaaS, and IaaS?
Software as a Service (SaaS) refers to using non-local software: the user purchases time and
12.52 What is Big Data?
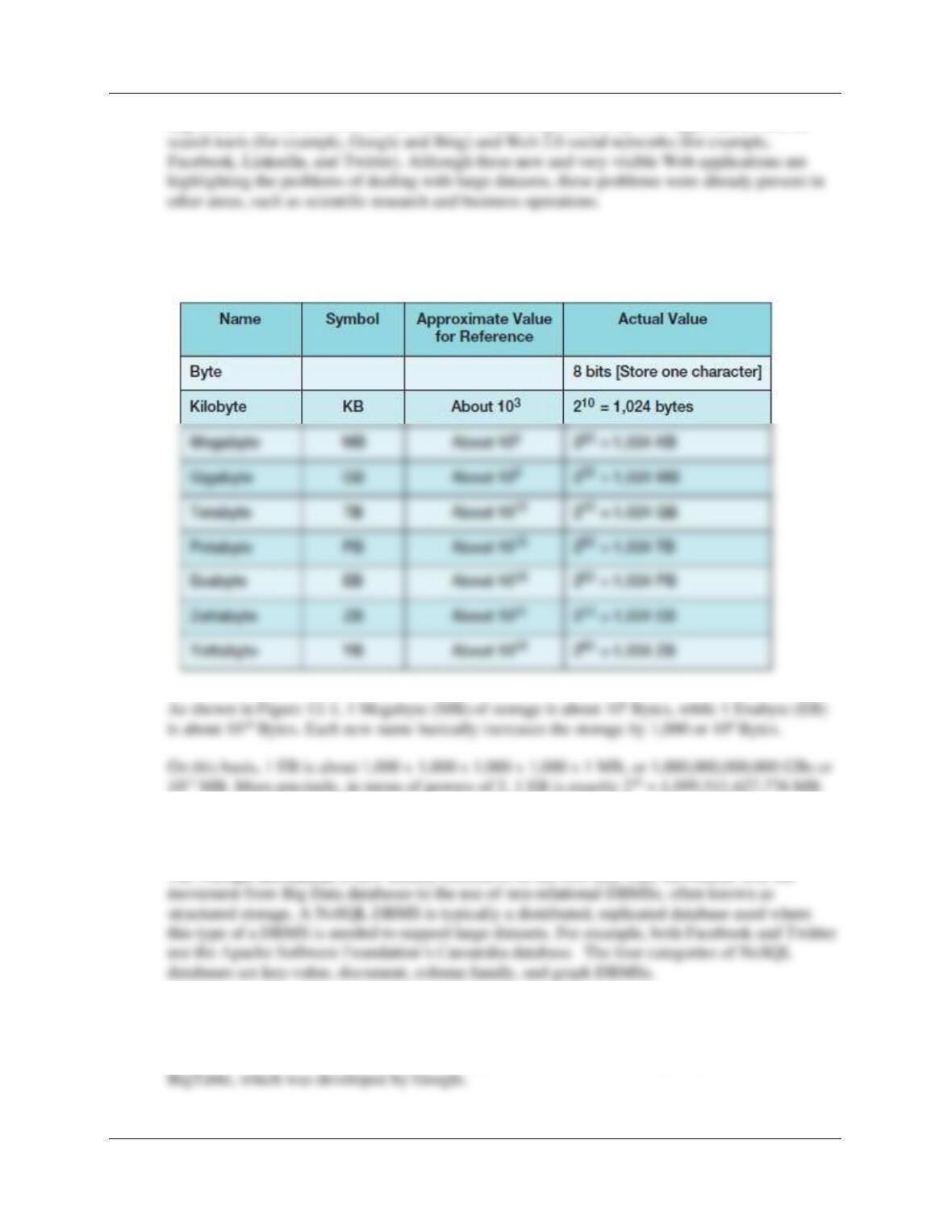
Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
Page 12-15
Big Data is the current term for the enormous datasets generated by Web applications such as
12.53 Based on Figure 12-1, what is the relationship between 1 MB of storage and 1EB of
storage?
12.54 What is the NoSQL movement? What are the four categories of NoSQL databases used
in this book?
The NoSQL movement is now usually referred to as the Not only SQL movement. It is the
12.55 What were the first two nonrelational data stores to be developed, and who developed
them?
The first two nonrelational data stores were Dynamo, which was developed by Amazon.com, and

Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
Page 12-16
12.56 As illustrated in Figure 12–33, what is column family database storage, and how are
column family database storage systems organized? How do structured storage systems
compare to RDBMS systems?
A generalized structured storage system (in this case, a column family database) is shown in
Figure 12-33. The column family equivalent of a relational DBMS (RDBMS) table has a very
different construction. Although similar terms are used, they do not mean the same thing that they
mean in a relational DBMS. The smallest unit of storage is called a column, but it is really the
equivalent of an RDBMS table cell (the intersection of an RDBMS row and column). A column
consists of three elements: the column name, the column value or datum, and a timestamp to
record when the value was stored in the column. This is shown in Figure 12-33(a) by the
LastName column, which stores the LastName value Able.

Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
Page 12-17
column family. This is illustrated in Figure 12-33(c) by the Customer column family, which
consists of three rows of data on customers.
12.57 Explain MapReduce processing.
The MapReduce process is used to break a large analytical task into smaller tasks, assign each
smaller task to a separate computer in the cluster, and then gather the results of each of those
tasks and combine them into the final product of the original tasks. The term Map refers to the
work done on each individual computer, and the term Reduce refers to the combining of the
individual results into the final result.

Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
Page 12-18
12.58 What is Hadoop, and what is the history of the development of Hadoop to its current
state? What are HBase and Pig?
Hadoop, which is now another Apache Software Foundation project, is a popular Big Data
❖ ANSWERS TO EXERCISES
12.59 Based on the discussion of the Heather Sweeney Designs operational database (HSD)
and dimensional database (HSD_DW) in the text, answer the following questions.
NOTE: The database design, table structure and data for the original Heather Sweeney Designs
(HSD) database data are included in the Heather Sweeny Designs Case Questions to Chapter 7.
The solution below is based on the complete HSD database as shown and created in the Chapter 7
HSD Case Questions.
A. Using the SQL statements shown in Figure 12-13, create the HSD_DW database
in a DBMS.
B. What possible transformations of data were made before HSD_DW was loaded
with data? List some possible transformations, showing the original format of the
HSD data and how they appear in the HSD_DW database
NOTE: These are the actual transformations, and do not include the same data columns in

Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
Page 12-19
C. Write the complete set of SQL statements necessary to load the transformed
data into the HSD_DW database.
See the files:
DBP–e15-MSSQL-HSD-DW-Insert-Data-TIMELINE.sql.
D. Populate the HSD_DW database using the SQL statements you wrote to answer
part C.
Run the *.sql scripts named in the previous question in the order shown.
E. Figure 12–35 shows the SQL code to create the SALES_FOR_RFM fact table
shown in Figure 12-18. Using those statements, add the SALES_FOR_RFM
table to your HSD_DW database.
See the file DBP-e15-MSSQL-HSD-DW-Create-SALES_FOR_RFM.sql.
SQL Server solution is in file DBP-e15-MSSQL-HSD-DW-PQ.sql:
SELECT C.CustomerID, C.CustomerName, C.City,
P.ProductNumber, P.ProductName,
T.Year, T.QuarterText,
SUM(PS.Total) AS TotalDollarSales
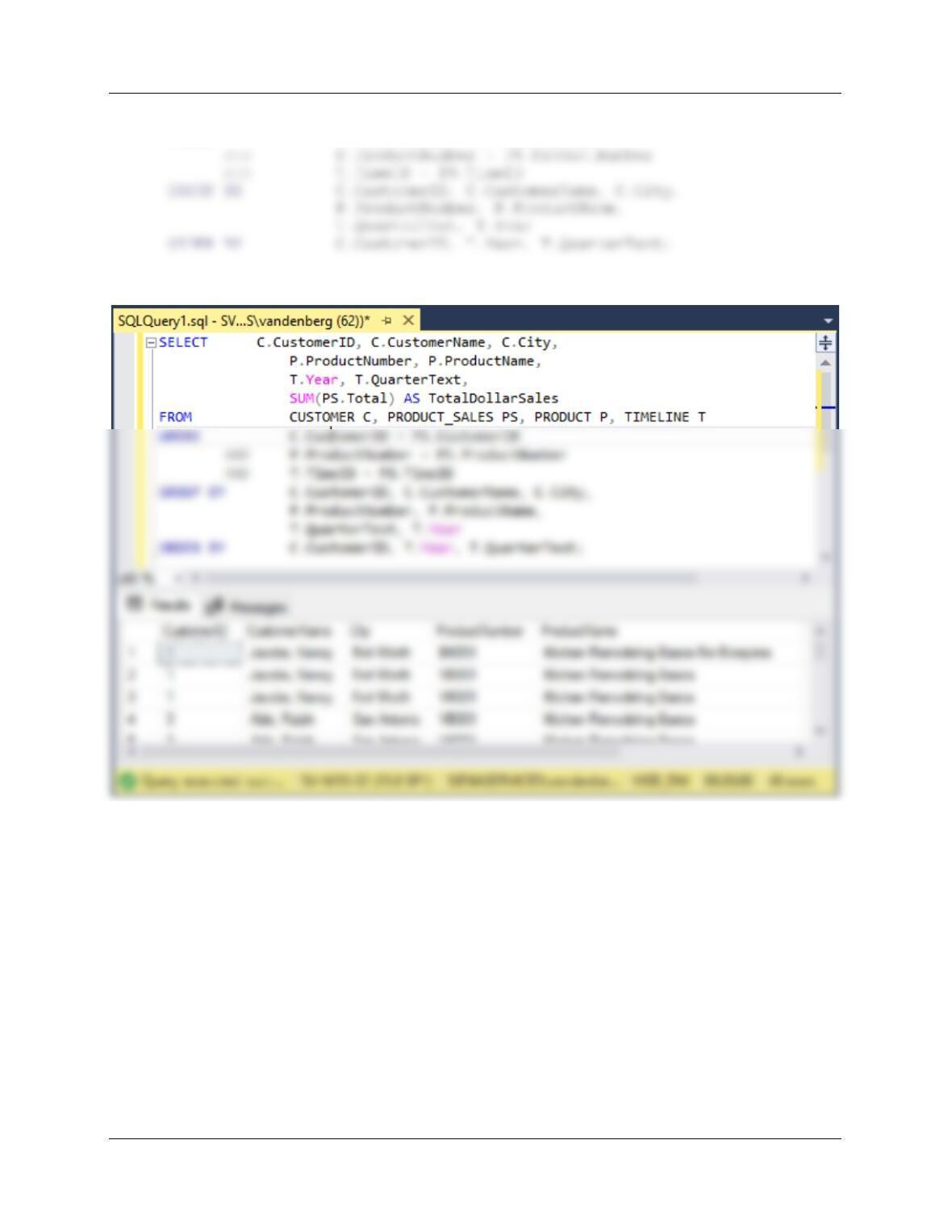
Chapter Twelve – Data Warehouses, Business Intelligence Systems, and Big Data
Page 12-20
FROM CUSTOMER C, PRODUCT_SALES PS, PRODUCT P, TIMELINE T
WHERE C.CustomerID = PS.CustomerID