
CHAPTER 5
Hashing
5.1 (a) On the assumption that we add collisions to the end of the list (which is the easier way if a hash table is
being built by hand), the separate chaining hash table that results is shown here.

(c)
(d) 1989 cannot be inserted into the table because hash2(1989) = 6, and the alternative locations 5, 1, 7, and 3
are already taken. The table at this point is as follows:
5.2 When rehashing, we choose a table size that is roughly twice as large and prime. In our case, the appropriate
new table size is 19, with hash function h(x) = x(mod 19).
(a) Scanning down the separate chaining hash table, the new locations are 4371 in list 1, 1323 in list 12, 6173

5.4 We must be careful not to rehash too often. Let p be the threshold (fraction of table size) at which we rehash
to a smaller table. Then if the new table has size N, it contains 2pN elements. This table will require
rehashing after either 2N − 2pN insertions or pN deletions. Balancing these costs suggests that a good choice
5.5 Here is a Java implementation of a singly linked list to support chaining. It consists of two source files,
LinkedList.java and Node.java. The rest of the hash table implementation would not need to be changed.
/** LinkedList.java – a singly linked list implementation
* to support separate chaining hash tables.
* The intent here is not to implement all methods in the Java API
* List interface – just the ones needed to support the separate

/** contains: We assume type T has an appropriate equals method.
*/
public boolean contains(T value)
{
{
head = n;
head.next = null;
}
else
{
// Go to the end of the list
Node curr = null;
if (head.data.equals(value))
{
head = head.next;
}
else
{
// At this point we know the value to remove is in the list,
// but not at the head of the list.

*/
public void print()
{
for (Node curr = head; curr != null; curr = curr.next)
System.out.printf(“%s\t”, curr.data.toString());
System.out.printf(“\n”);
}
}
/** Node.java
*/
}
}
5.6 No; this does not take deletions into account.
5.8 Cubic probing encounters slightly fewer collisions than quadratic probing, as seen in the following
simulation.
// Let’s simulate linear, quadratic, and cubic probimg.
// Is cubic probing any better than quadratic?

public static final int MAX = 9000000;
public static void main(String [] args)
{
int [] linear = new int [SIZE];
int [] quadratic = new int [SIZE];
int [] cubic = new int [SIZE];
++linearCollisions;
++offset;
hashCode += offset;
if (hashCode >= SIZE)
hashCode %= SIZE;
}
linear[hashCode] = 1;
}
}
for (int i = 0; i < MAX; ++i)
{
int hashCode = gen.nextInt(SIZE);
int offset = 0;
while (cubic[hashCode] == 1)
{

cubic[hashCode] = 1;
}
System.out.printf(“Here is the number of collisions for each type of
probing.\n”);
System.out.printf(“linear = %d\n”, linearCollisions);
5.9 In a good library implementation, the length method should be inlined.
5.10 Separate chaining hashing requires the use of links, which costs some memory, and the standard method of
implementing calls on memory allocation routines, which typically are expensive. Linear probing is easily
implemented, but performance degrades severely as the load factor increases because of primary clustering.
5.12 The old values would remain valid if the hashed values were less than the old table size.
5.13 Sorting the MN records and eliminating duplicates would require O(MN log MN) time using a standard
sorting algorithm. If terms are merged by using a hash function, then the merging time is constant per term

5.14 To each hash table slot, we can add an extra data member that we’ll call whereOnStack, and we can keep an
extra stack. When an insertion is first performed into a slot, we push the address (or number) of the slot onto
5.16 If the switch expression and case values are String objects, then a compiler can use the String class
5.19 (a) The cost of an unsuccessful search equals the cost of an insertion.
5.20 public class Map<KeyType, ValueType>
{
public Map()
{
items = new
QuadraticProbingHashTable<Entry<KeyType,ValueType>>();
}

e = items.find(e);
return e.val;
}
public boolean isEmpty()
{ return items.isEmpty(); }
public int hashCode()
{
return key.hashCode();
}
//public boolean equals( Entry<KeyType, ValueType> rhs )
public boolean equals( Object rhs )
The QuadraticProbingHashTable.java file needs these additional methods (not given in the text) for the
above solution to work:
public boolean isEmpty( )
{
return currentSize == 0;

5.22 Markov’s inequality states that there is at most a probability of 1/n of experiencing a “score” or expected
value of n or greater. One way to prove it is to view it as a continuous version of the pigeonhole principle.
Suppose Markov’e inequality does not hold. Then, it is possible to have a probability of 1/n of
experiencing an expected value of at least n+e, where e > 0. The sum of these expected values would be
5.23 The probability of a rehash (failed insertion) at the point when the table is half full is low, on the order of
1% or less. The probability falls with increased table size. Below are the results of two trials with random
insertion data. The probabilities may be even lower if we modify the hopscotch table to continue linear
probing past the end of the table to wrap around to the beginning.
Table size
MAX_DIST
Load factor
Number of trials
Probability of rehash
0.5
1,000,000
5.24 Here is a Java implementation of a Hopscotch hash table. It consists of two source files, Hopscotch.java
and Cell.java.

public class Hopscotch
{
private int maxDist;
private int maxSize;
private Cell [] table;
public Hopscotch(int dist, int size)
{
// Attempt to put the data into the table at index hashValue.
// If that space is taken, then we do linear probing, but only
// within the limitation of the MAX_DIST.
// Also make the approprate change to the “hop” entry in the cell.
// If linear probing goes too far, then we must follow the eviction\
// procedure explained in the text.
// First, see if this cell is occupied or available.
boolean available = table[hashValue].data == null;
{
//System.out.printf(“Need to try some linear probing.\n”);
boolean successfullyPlaced = false;
for (int i = 1; i < maxDist; ++i)
{
// Reject a table index that is too high!
if (hashValue + i >= maxSize)

}
}
// The only problem left is if we did not successfully insert the data.
if (! successfullyPlaced)
{
//System.out.printf(“Need to evict\n”);
// First, find the linear probing destination (which is too far).
boolean found = false;
// Search other data that could possibly fit into the available cell.
// Because of the maxDist restriction, a candidate would need to have
// a hash value no lower than availableCell – maxDist + 1.
// In other words:
// For each hashValue
// from availableCell – maxDist + 1 to availableCell – 1,
// Look at the “hop” bit vector to see which data that has this
// hash value can possibly be moved into the available cell.
// If there isn’t any, then proceed to the next hash value.
// Perform the appropriate eviction.
// Update the value of availableCell to be the place we evicted from.

bit
table[i].hop |= 1 << (availableCell – i); // turn on new
bit
//System.out.println(this);
found = true;
break;
}
if (found)
// is sufficiently small. This means we can go ahead and put the
// desired data value into the hopscotch table.
table[availableCell].data = data;
table[hashValue].hop |= 1 << (availableCell – hashValue);
return true;
}
}
return true; // please the compiler
}
public String toString()
{

else
break;
}
while (high >= 0)
{
if (table[high].data == null)
–high;
else
build.append(“1”);
build.append(“\n”);
}
}
return build.toString();
}
}
/** Cell.java – each cell in the hopscotch table needs
* two pieces of information: the data being stored,
* and the “hop” bit vector.
*/
public class Cell
{

Implementation
Time (ms)
Hopscotch
150
Separate chaining
5.25 Here is a Java implementation of a cuckoo hash table. Diagnostic output can, of course, be removed.
// To mimic the “classic” cuckoo hash table, as shown in the examples
// given in Figures 5.26-5.33 in the text,
public class CuckooHashTable
{
public void makeEmpty()
{
for (int i = 0; i < contents.length; ++i)
for (int j = 0; j < contents[0].length; ++j)
contents[i][j] = null;
}
// For Cuckoo hashing, we need to be ready to compute the value
// of an n-th hash code. Multiply the string’s native hash code
// by the table number (e.g. 1 or 2…), and mod by the logical size.

if (contents[desiredRow][desiredCol] == null)
{
contents[desiredRow][desiredCol] = value;
break;
}
// The case of having to evict something already there.
else
{
String victim = contents[desiredRow][desiredCol];
contents[desiredRow][desiredCol] = value;
}
}
}
}
5.26 To support d hash functions, the only modification necessary in the implementation given in 5.25 is to
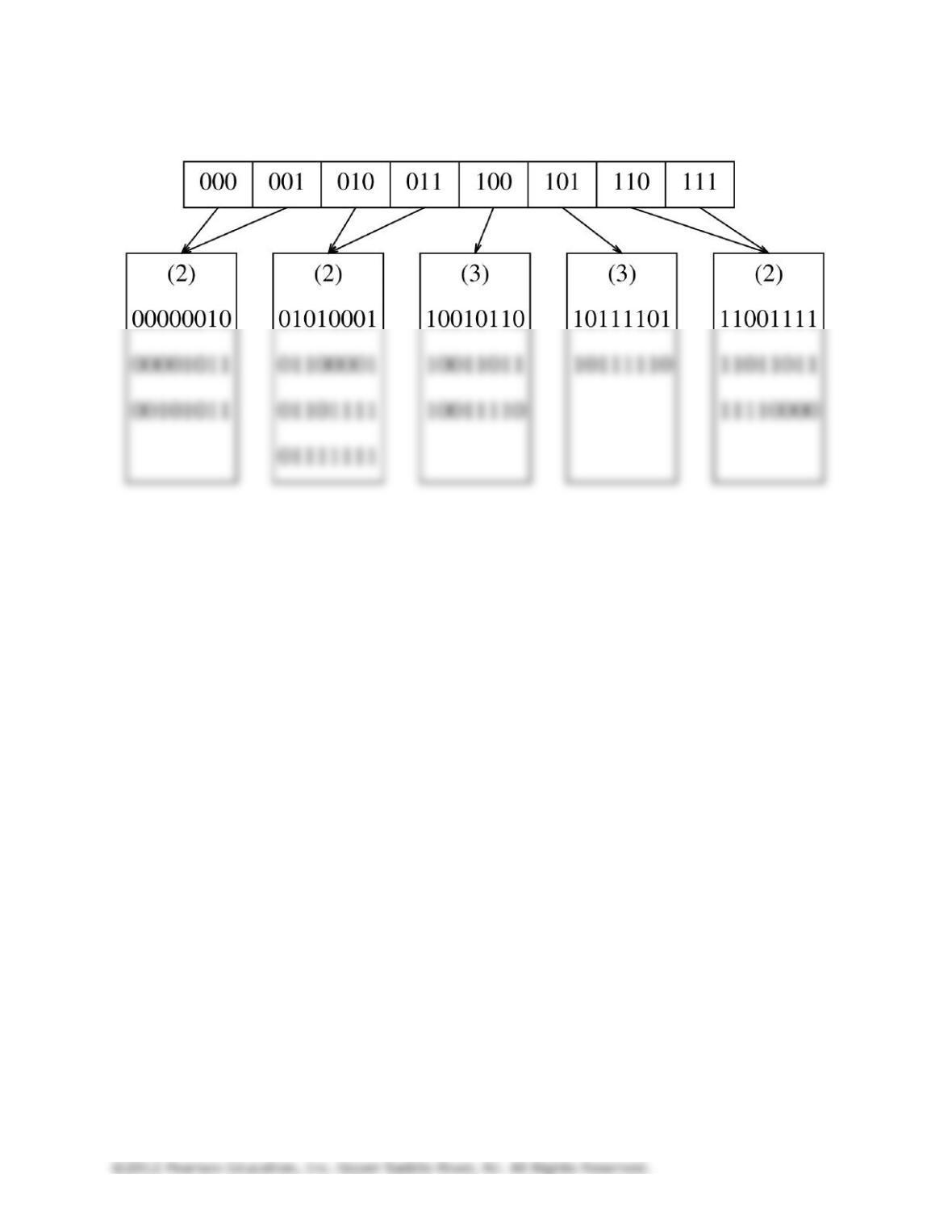
5.27