
23. a.
/ 2.30 / 50 .3253
xn
= = =
At
x
= 22.18,
22.18 21.68 1.54
.3253
/
x
zn
−−
= = =
P(z ≤ 1.54) = .9382
x
b.
/ 2.05 / 50 .2899
xn
= = =
At
x
= 19.30,
19.30 18.80 1.72
.2899
/
x
zn
−−
= = =
P(z ≤ 1.72) = .9573
At
x
= 18.30, z = -1.72, P(z < -1.72) = .0427, thus
x
c. In part (b) we have a higher probability of obtaining a sample mean within $.50 of the population
mean because the standard error for female graduates (.2899) is smaller than the standard error for
male graduates (.3253).
d. With n = 120,
/ 2.05 / 120 .1871
xn
= = =
At
x
= 18.50,
18.50 18.80 1.60
.1871
z−
= = −
P(
x
< 18.50) = P(z < -1.60) = .0548
/ 4 / 30 .7303
xn
= = =
b. Within 1 inch means 21
x
23
x
23 22 1.37
21 22 1.37

c.
/ 4 / 45 .5963
xn
= = =
Within 1 inch means 41
x
43
43 42 1.68
.5963
z−
==
41 42 1.68
.5963
z−
= = −
P(41
x
43) = P(–1.68 ≤ z ≤ 1.68) = .9535 – .0465 = .9070
larger.
25.
= 183
= 50
a. n = 30 Within 8 means
175 191x
8.88
/ 50 / 30
x
zn
−
= = =
P(175
x
191) = P(-.88 z .88) = .8106 – .1894 = .6212
175 191x
x
175 191x
81.60
/ 50 / 100
x
zn
−
= = =
P(175
x
191) = P(-1.60 z 1.60) = .9452 – .0548 = .8904
d. None of the sample sizes in parts (a), (b), and (c) are large enough. The sample size will need to
be greater than n = 100, which was used in part (c).
b. With the finite population correction factor

x
N n
Nn
=−
−=−
−=
1
4000 40
4000 1
82
40 129
..
Without the finite population correction factor
130
130 154
. . .
P(z < -1.54) = .0618
Probability = .9382 – .0618 = .8764
Using Excel:
b.
(1 ) .40(.60) .0490
100
p
pp
n
−
= = =
c. Normal distribution with E(
p
) = .40 and
p
= .0490
d. It shows the probability distribution for the sample proportion
p
.
(1 ) .40(.60) .0346
200
p
pp
n
−
= = =
Within ± .03 means .37 ≤
p
≤ .43
.03 .87
.0346
p
pp
z
−
= = =
P(z ≤ .87) = .8078

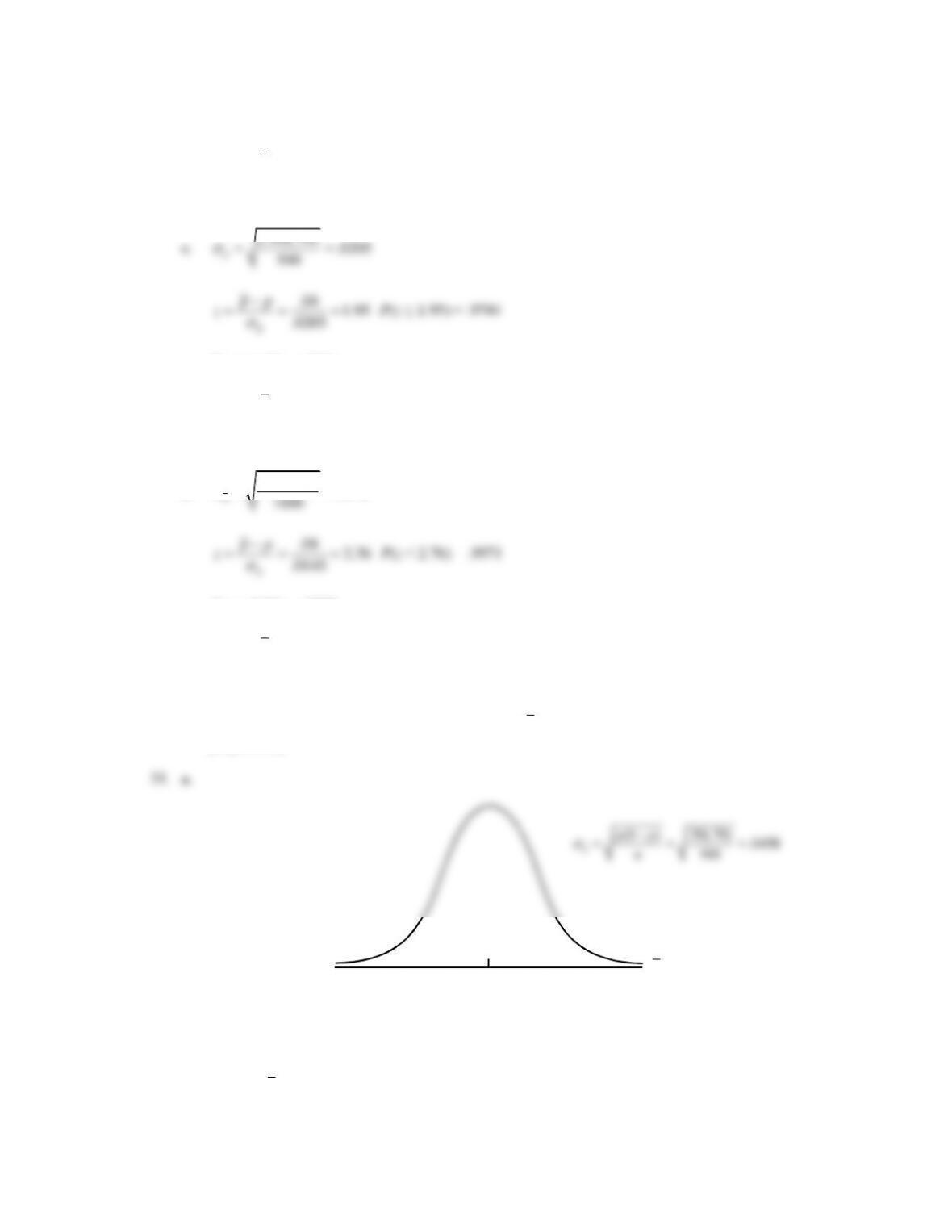
P(z < -1.23) = .1093
P(.26 ≤
p
≤ .34) = .8907 – .1093 = .7814
Using Excel: NORM.DIST(.34,.30,.0324,TRUE)-NORM.DIST(.26,.30,.0324,TRUE) = .7830
(.30)(.70) .0205
P(z < -1.95) = .0256
P(.26 ≤
p
≤ .34) = .9744 – .0256 = .9488
Using Excel: NORM.DIST(.34,.30,.0205,TRUE)-NORM.DIST(.26,.30,.0205,TRUE) = .9490
d.
(.30)(.70) .0145
1000
p
==
P(z < -2.76) = .0029
P(.26 ≤
p
≤ .34) = .9971 – .0029 = .9942
Using Excel: NORM.DIST(.34,.30,.0145,TRUE)-NORM.DIST(.26,.30,.0145,TRUE) = .9942
e. With a larger sample, there is a higher probability
p
will be within .04 of the population
proportion p.
The normal distribution is appropriate because np = 100(.30) = 30 and n(1 – p) = 100(.70) = 70 are
both greater than 5.
b. P (.20
p
.40) = ?
.30
(1 ) .30(.70) .0458
100
p
pp
n
−
= = =
p

.40 .30 2.18
.0458
z−
==
P(z ≤ 2.18) = .9854
P(z < -2.18) = .0146
P(.20 ≤
p
≤ .40) = .9854 – .0146 = .9708
Using Excel: NORM.DIST(.40,.30,.0458,TRUE)-NORM.DIST(.20,.30,.0458,TRUE) = .9710
c. P (.25
p
.35) = ?
.35 .30 1.09
.0458
z−
==
P(z ≤ 1.09) = .8621
P(z < -1.09) = .1379
P(.25 ≤
p
≤ .35) = .8621 – .1379 = .7242
Using Excel: NORM.DIST(.35,.30,.0458,TRUE)-NORM.DIST(.25,.30,.0458,TRUE) = .7250
(1 ) .55(1 .55) .0352
p
pp
−−
= = =
200
n
b. Within ± .05 means .50 ≤
p
≤ .60
.60 .55 1.42
.0352
p
pp
z
−−
= = =
.50 .55 1.42
.0352
p
pp
z
−−
= = = −
(1 ) .45(1 .45) .0352
200
p
pp
n
−−
= = =
d.
(1 ) .45(1 .45) .0352
200
p
pp
n
−−
= = =

e. No, the probabilities are exactly the same. This is because
p
, the standard error, and the width of
the interval are the same in both cases. Notice the formula for computing the standard error. It
involves p(1 – p). So whenever p(1 – p) does not change, the standard error will be the same. In
part (b), p = .55 and 1 – p = .45. In part (d), p = .45 and 1 – p = .55.
f. For n = 400,
(1 ) .55(1 .55) .0249
400
p
pp
n
−−
= = =
Using Excel NORM.DIST(.60,.55,.0249,TRUE)-NORM.DIST(.50,.55,.0249,TRUE) = .9554
The probability is larger than in part (b). This is because the larger sample size has reduced the
standard error from .0352 to .0249.
33. a. Normal distribution
( ) .12Ep=
(1 ) (.12)(1 .12) .0140
540
p
pp
n
−−
= = =
b.
.03 2.14
.0140
p
pp
z
−
= = =
P(z ≤ 1.94) = .9838

E(
p
) = .42
(1 ) (.42)(.58) .0285
300
p
pp
n
−
b.
.03 1.05
.0285
p
pp
z
−
= = =
P(z ≤ 1.05) = .8531
P(z < -1.05) = .1469
P(.39 ≤
p
≤ .45) = .8531 – .1469 = .7062
P(z < -1.75) = .0401
P(.37 ≤
p
≤ .47) = .9599 – .0401 = .9198
Using Excel: NORM.DIST(.47,.42,.0285,TRUE)-NORM.DIST(.37,.42,.0285,TRUE) = .9206
d. The probabilities would increase. This is because the increase in the sample size makes the standard
error,
p
, smaller.
(1 ) .75(1 .75) .0306
200
p
pp
n
−−
= = =
d.
.04 1.31
.0306
.75(1 .75)
200
pp
z−
= = =
−
P(z ≤ 1.31) = .9049

P(z < -1.31) = .0951
P(.71
p
.79) = P(-1.31 z 1.31) = .9049 – .0951 = .8098
Using Excel: NORM.DIST(.79,.75,.0306,TRUE)-NORM.DIST(.71,.75,.0306,TRUE) = .8089
d. The probability of the sample proportion being within .04 of the population mean was reduced from
.9501 to .8089. So there is a gain in precision by increasing the sample size from 200 to 450. If the
extra cost of using the larger sample size is not too great, we should probably do so.