
Introduction to Econometrics, 3e (Stock)
Chapter 14 Introduction to Time Series Regression and Forecasting
14.1 Multiple Choice
1) Pseudo out of sample forecasting can be used for the following reasons with the exception of
A) giving the forecaster a sense of how well the model forecasts at the end of the sample.
B) estimating the RMSFE.
C) analyzing whether or not a time series contains a unit root.
D) evaluating the relative forecasting performance of two or more forecasting models.
2) Autoregressive distributed lag models include
A) current and lagged values of the error term.
B) lags of the dependent variable, and lagged values of additional predictor variables.
C) current and lagged values of the residuals.
D) lags and leads of the dependent variable.
3) Time series variables fail to be stationary when
A) the economy experiences severe fluctuations.
B) the population regression has breaks.
C) there is strong seasonal variation in the data.
D) there are no trends.
4) Departures from stationarity
A) jeopardize forecasts and inference based on time series regression.
B) occur often in cross–sectional data.
C) can be made to have less severe consequences by using log–log specifications.
D) cannot be fixed.
5) In order to make reliable forecasts with time series data, all of the following conditions are needed with
the exception of
A) coefficients having been estimated precisely.
B) the regression having high explanatory power.
C) the regression being stable.
D) the presence of omitted variable bias.

6) The first difference of the logarithm of Yt equals
A) the first difference of Y.
B) the difference between the lead and the lag of Y.
C) approximately the growth rate of Y when the growth rate is small.
D) the growth rate of Y exactly.
7) The time interval between observations can be all of the following with the exception of data collected
A) daily.
B) by decade.
C) bi–weekly.
D) across firms.
8) One reason for computing the logarithms (ln), or changes in logarithms, of economic time series is that
A) numbers often get very large.
B) economic variables are hardly ever negative.
C) they often exhibit growth that is approximately exponential.
D) natural logarithms are easier to work with than base 10 logarithms.
9) The jth autocorrelation coefficient is defined as
A)
( )
( ) ( )
cov , 1
var var 1
tt
Tt
YY
YY
−
−
.
B)
( )
( )
( )
cov , 1
var var
tt
t t j
Y Y j
YY
−
−−
.
C)
( )
( ) ( )
cov ,
var var
tt
tt
Yu
Yu
.
D)
( )
( )
( )
cov ,
var var
tt
t t j
Y Y j
YY
−
−
.
10) Negative autocorrelation in the change of a variable implies that
A) the variable contains only negative values.
B) the series is not stable.
C) an increase in the variable in one period is, on average, associated with a decrease in the next.
D) the data is negatively trended.

11) An autoregression is a regression
A) of a dependent variable on lags of regressors.
B) that allows for the errors to be correlated.
C) model that relates a time series variable to its past values.
D) to predict sales in a certain industry.
12) The root mean squared forecast error (RMSFE) is defined as
A)
1
ˆ
T T T
E Y Y −
−
.
B)
( )
2
11
ˆ
T T T
E Y Y
++
−
.
C)
( )
2
1
ˆ
T T T
YY−
−
.
D)
( )
1
ˆ
T T T
E Y Y −
−
.
13) One of the sources of error in the RMSFE in the AR(1) model is
A) the error in estimating the coefficients β0 and β1.
B) due to measuring variables in logarithms.
C) that the value of the explanatory variable is not known with certainty when making a forecast.
D) the model only looks at the previous period’s value of Y when the entire history should be taken into
account.
14) The forecast is
A) made for some date beyond the data set used to estimate the regression.
B) another word for the OLS predicted value.
C) equal to the residual plus the OLS predicted value.
D) close to 1.96 times the standard deviation of Y during the sample.
15) The AR(p) model
A) is defined as Yt = β0 + βpYt–p + ut.
B) represents Yt as a linear function of p of its lagged values.
C) can be represented as follows: Yt = β0 + β1Xt + βpYt–p + ut.
D) can be written as Yt = β0 + β1Yt–1 + ut–p.

16) The ADL(p,q) model is represented by the following equation
A) Yt = β0 + βpYt–p + δqXt–q + ut.
B) Yt = β0 + β1Yt–1 + β2Yt–2 + … + βpYt–p + δqut–q.
C) Yt = β0 + β1Yt–1 + β2Yt–2 + … + βpYt–p + δ0 + δ1Xt–1 + ut–q.
D) Yt = β0 + β1Yt–1 + β2Yt–2 + … + βpYt–p + δ1Xt–1 + δ2Xt–2 + … + δqXt–q + ut.
17) Stationarity means that the
A) error terms are not correlated.
B) probability distribution of the time series variable does not change over time.
C) time series has a unit root.
D) forecasts remain within 1.96 standard deviation outside the sample period.
18) The Times Series Regression with Multiple Predictors
A) is the same as the ADL(p,q) with additional predictors and their lags present.
B) gives you more than one prediction.
C) cannot be estimated by OLS due to the presence of multiple lags.
D) requires that the k regressors and the dependent variable have nonzero, finite eighth moments.
19) The Granger Causality Test
A) uses the F–statistic to test the hypothesis that certain regressors have no predictive content for the
dependent variable beyond that contained in the other regressors.
B) establishes the direction of causality (as used in common parlance) between X and Y in addition to
correlation.
C) is a rather complicated test for statistical independence.
D) is a special case of the Augmented Dickey–Fuller test.
20) To choose the number of lags in either an autoregression or in a time series regression model with
multiple predictors, you can use any of the following test statistics with the exception of the
A) F–statistic.
B) Akaike Information Criterion.
C) Bayes Information Criterion.
D) Augmented Dickey–Fuller test.
21) The random walk model is an example of a
A) deterministic trend model.
B) binomial model.
C) stochastic trend model.
D) stationary model.

22) Problems caused by stochastic trends include all of the following with the exception of
A) the estimator of an AR(1) is biased towards zero if it’s true value is one.
B) the model can no longer be estimated by OLS.
C) t–statistics on regression coefficients can have a nonnormal distribution, even in large samples.
D) the presence of spurious regression..
23) The Augmented Dickey Fuller (ADF) t–statistic
A) has a normal distribution in large samples.
B) has the identical distribution whether or not a trend is included or not.
C) is a two–sided test.
D) is an extension of the Dickey–Fuller test when the underlying model is AR(p) rather than AR(1).
24) If a “break” occurs in the population regression function, then
A) inference and forecasting are compromised when neglecting it.
B) an Augmented Dickey Fuller test, rather than the Dickey Fuller test, should be used to test for
stationarity.
C) this suggests the presence of a deterministic trend in addition to a stochastic trend.
D) forecasting, but not inference, is unaffected, if the break occurs during the first half of the sample
period.
25) You should use the QLR test for breaks in the regression coefficients, when
A) the Chow F–test has a p value of between 0.05 and 0.10.
B) the suspected break data is not known.
C) there are breaks in only some, but not all, of the regression coefficients.
D) the suspected break data is known.
26) The Bayes–Schwarz Information Criterion (BIC) is given by the following formula
A) BIC(p) = ln [ ] + (p+1)
B) BIC(p) = ln [ ] + (p+1)
C) BIC(p) = ln [ ] – (p+1)
D) BIC(p) = ln [ ] × (p+1)

27) The Akaike Information Criterion (AIC) is given by the following formula
A) AIC(p) = ln [ ] + (p+1)
B) AIC(p) = ln [ ] + (p+1)
C) AIC(p) = ln [ ] +
D) AIC(p) = ln [ ] × (p+1)
28) The BIC is a statistic
A) commonly used to test for serial correlation
B) only used in cross–sectional analysis
C) developed by the Bank of England in its river of blood analysis
D) used to help the researcher choose the number of lags in an autoregression
29) The AIC is a statistic
A) that is used as an alternative to the BIC when the sample size is small (T < 50)
B) often used to test for heteroskedasticity
C) used to help a researcher chose the number of lags in a time series with multiple predictors
D) all of the above
30) The formulae for the AIC and the BIC are different. The
A) AIC is preferred because it is easier to calculate
B) BIC is preferred because it is a consistent estimator of the lag length
C) difference is irrelevant in practice since both information criteria lead to the same conclusion
D) AIC will typically underestimate p with non–zero probability

7
14.2 Essays and Longer Questions
1) You set out to forecast the unemployment rate in the United States (UrateUS), using quarterly data
from 1960, first quarter, to 1999, fourth quarter.
(a) The following table presents the first four autocorrelations for the United States aggregate
unemployment rate and its change for the time period 1960 (first quarter) to 1999 (fourth quarter).
Explain briefly what these two autocorrelations measure.
First Four Autocorrelations of the U.S. Unemployment Rate and Its Change,
1960:I – 1999:IV
Lag
Unemployment Rate
Change of
Unemployment Rate
1
0.97
0.62
2
0.92
0.32
3
0.83
0.12
4
0.75
–0.07
(b) The accompanying table gives changes in the United States aggregate unemployment rate for the
period 1999:I–2000:I and levels of the current and lagged unemployment rates for 1999:I. Fill in the blanks
for the missing unemployment rate levels.
Changes in Unemployment Rates in the United States
First Quarter 1999 to First Quarter 2000
Quarter
U.S. Unemployment
Rate
First Lag
Change in
Unemployment Rate
1999:I
4.3
4.4
–0.1
1999:II
0.0
1999:III
–0.1
1999:IV
–0.1
2000:I
–0.1
(c) You decide to estimate an AR(1) in the change in the United States unemployment rate to forecast the
aggregate unemployment rate. The result is as follows:
= –0.003 + 0.621 △ UrateUSt–1, R2 = 0.393, SER = 0.255
(0.022) (0.106)

8
The AR(1) coefficient for the change in the inflation rate was 0.211 and the regression R2 was 0.04. What
does the difference in the results suggest here?
(d) The textbook used the change in the log of the price level to approximate the inflation rate, and then
predicted the change in the inflation rate. Why aren’t logarithms used here?
(e) If much of the forecast error arises as a result of future error terms dominating the error resulting from
estimating the unknown coefficients, then what is your best guess of the RMSFE here?
(f) The actual unemployment rate during the fourth quarter of 1999 is 4.1 percent, and it decreased from
the third quarter to the fourth quarter by 0.1 percent. What is your forecast for the unemployment rate
level in the first quarter of 1996?
(g) You want to see how sensitive your forecast is to changes in the specification. Given that you have
estimated the regression with quarterly data, you consider an AR(4) model. This results in the following
output
= –0.005 + 0.663 △UrateUSt–1 – 0.082 UrateUSt–2
(0.022) (0.125) (0.139)
+ 0.106 UrateUSt–3 – 0.176 △ UrateUSt–4 , R2 = 0.416, SER = 0.253
(0.117) (0.091)
What is your forecast for the unemployment rate level in 2000:I? Compare the forecast error of the AR(4)
model with the forecast error of the AR(1) model.
(h) There does not seem to be much difference in the forecast of the unemployment rate level, whether
you use the AR(1) or the AR(4). Given the various information criteria and the regression R2 below,
which model should you use for forecasting?
p BIC AIC R2
0 0.604 0.624 0.000
1 0.158 0.1181 0.393
2 0.185 0.125 0.397
3 0.217 0.138 0.400
4 0.218 0.1183 0.416
5 0.249 0.130 0.417
6 0.277 0.138 0.420

10
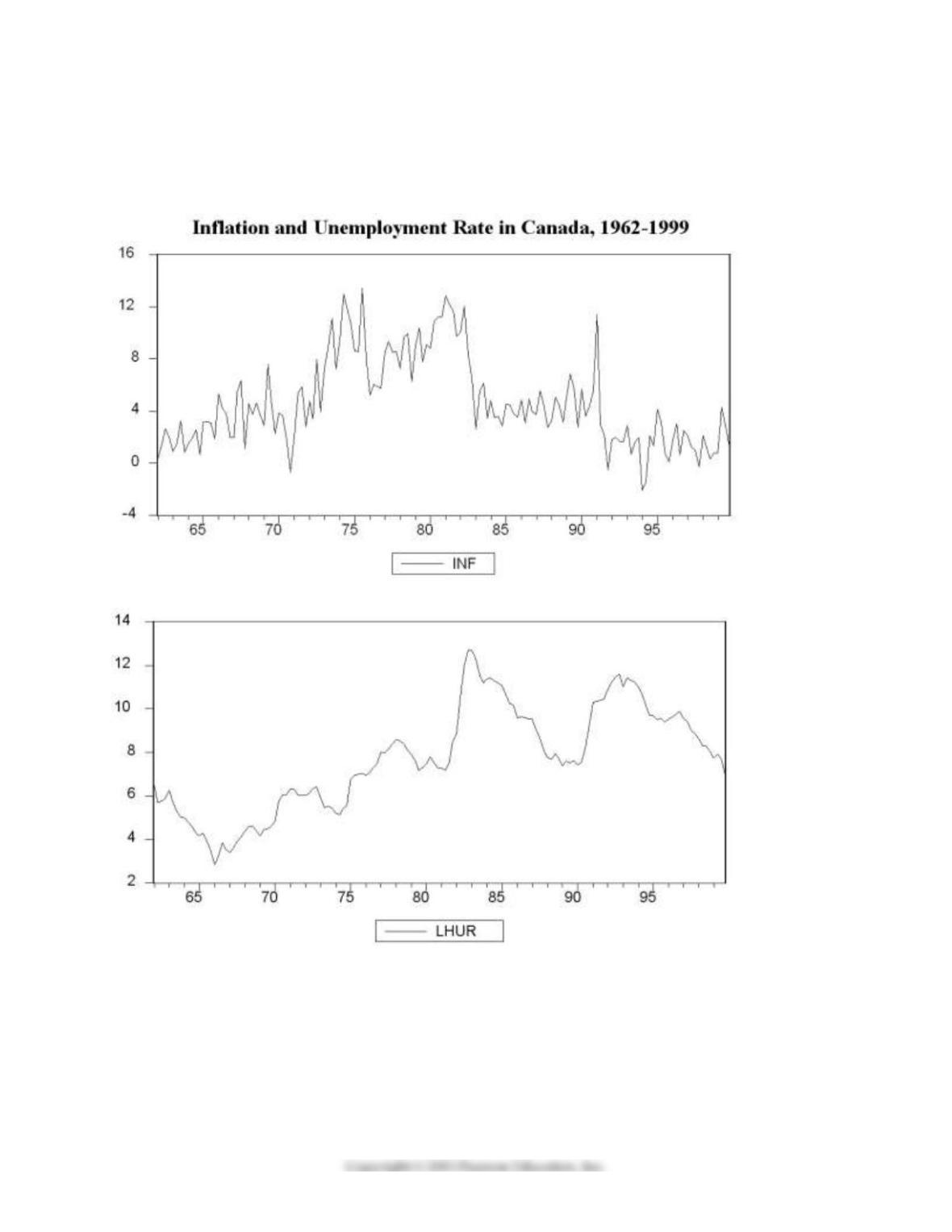
2) You have collected quarterly data on Canadian unemployment (UrateC) and inflation (InfC) from 1962
to 1999 with the aim to forecast Canadian inflation.
(a) To get a better feel for the data, you first inspect the plots for the series.
Inspecting the Canadian inflation rate plot and having calculated the first autocorrelation to be 0.79 for
the sample period, do you suspect that the Canadian inflation rate has a stochastic trend? What more
formal methods do you have available to test for a unit root?

11
(b) You run the following regression, where the numbers in parenthesis are homoskedasticity–only
standard errors:
= 0.49– 0.10 Inft–1 – 0.39 △InfCt–1 – 0.33 △InfCt–2 – 0.21 △InfCt–3 + 0.05 △InfCt–4
(0.28) (0.05) (0.09) (0.09) (0.09) (0.08)
Test for the presence of a stochastic trend. Should you have used heteroskedasticity–robust standard
errors? Does the fact that you use quarterly data suggest including four lags in the above regression, or
how should you determine the number of lags?
(c) To forecast the Canadian inflation rate for 2000:I, you estimate an AR(1), AR(4), and an ADL(4,1)
model for the sample period 1962:I to 1999:IV. The results are as follows:
= 0.002 – 0.31 △InfCt–1
(0.014) (0.10)
= 0.021 – 0.46 ΔInfCt–1 – 0.39 ΔInfCt–2 – 0.25 ΔInfCt–3 + 0.03 ΔInfCt–4
(0.158) (0.10) (0.11) (0.08) (0.07)
= 1.279 – 0.51 ΔInfCt–1 – 0.44 ΔInfCt–2 – 0.30 ΔInfCt–3 – 0.02 ΔInfCt–4
(0.57) (0.10) (0.11) (0.09) (0.08)
– 0.16 UrateCt–1
(0.07)
In addition, you have the following information on inflation in Canada during the four quarters of 1999
and the first quarter of 2000:
Inflation and Unemployment in Canada, First Quarter 1999 to First Quarter 2000
Quarter
Unemployment
Rate
(UrateCt)
Rate of
Inflation at an
Annual Rate
(Inft)
First Lag
(Inft–1)
Change in
Inflation
(△Inft)
1999:I
7.7
0.8
0.8
0.0
1999:II
7.9
4.3
0.8
3.5
1999:III
7.7
2.9
4.3
–1.4
1999:IV
7.0
1.3
2.9
–1.5
2000:I
6.8
2.1
1.3
0.8
For each of the three models, calculate the predicted inflation rate for the period 2000:I and the forecast
error.
(d) Perform a test on whether or not Canadian unemployment rates Granger–cause the Canadian inflation
rate.

13
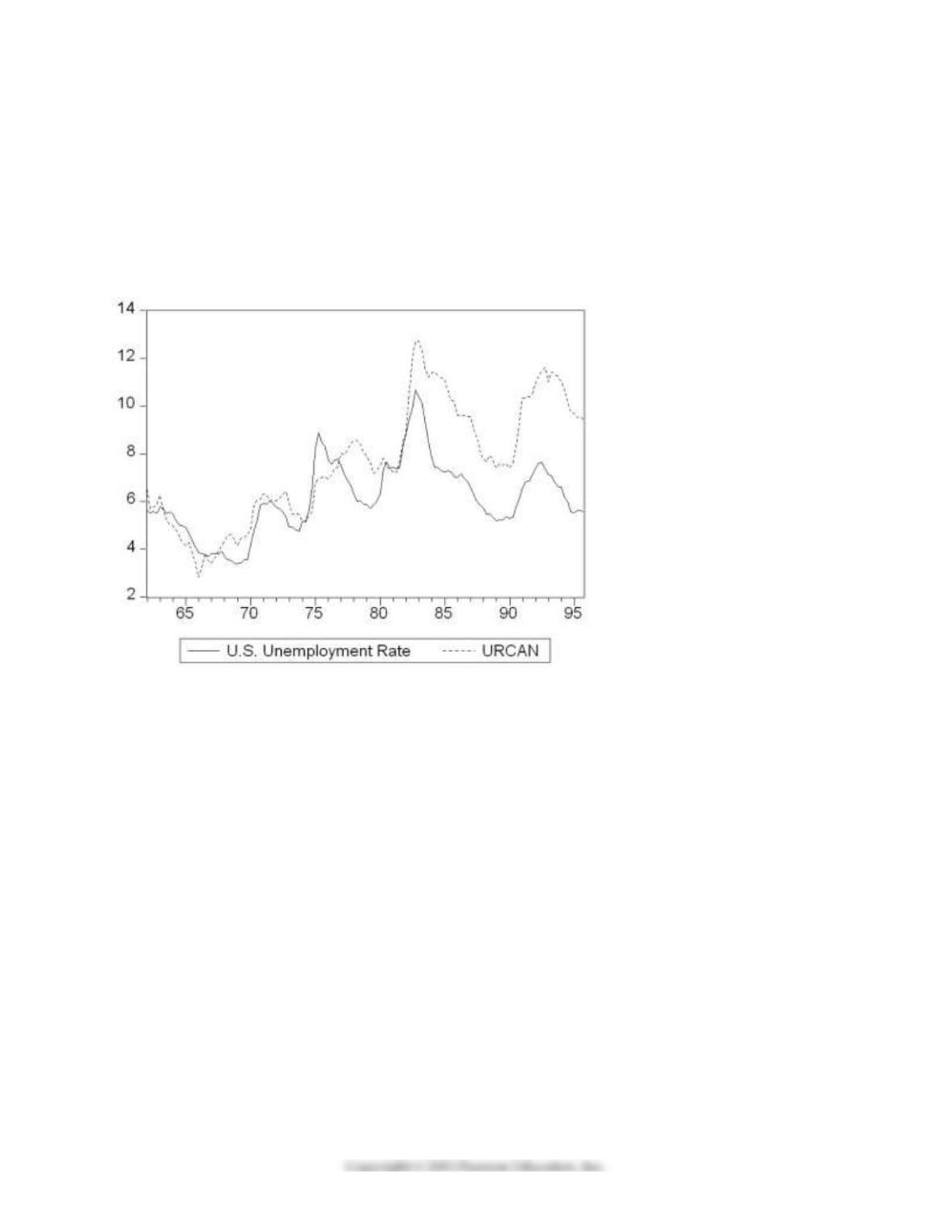
3) There is some evidence that the Phillips curve has been unstable during the 1962 to 1999 period for the
United States, and in particular during the 1990s. You set out to investigate whether or not this instability
also occurred in other places. Canada is a particularly interesting case, due to its proximity to the United
States and the fact that many features of its economy are similar to that of the U.S.
(a) Reading up on some of the comparative economic performance literature, you find that Canadian
unemployment rates were roughly the same as U.S. unemployment rates from the 1920s to the early
1980s. The accompanying figure shows that a gap opened between the unemployment rates of the two
countries in 1982, which has persisted to this date.
Inspection of the graph and data suggest that the break occurred during the second quarter of 1982. To
investigate whether the Canadian Phillips curve shows a break at that point, you estimate an ADL(4,4)
model for the sample period 1962:I–1999:IV and perform a Chow test. Specifically you postulate that the
constant and coefficients of the unemployment rates changed at that point. The F–statistic is 1.96. Find the
critical value from the F–table and test the null hypothesis that a break occurred at that time. Is there any
reason why you should be skeptical about the result regarding the break and using the Chow–test to
detect it?
(b) You consider alternative ways to test for a break in the relationship. The accompanying figure shows
the F–statistics testing for a break in the ADL(4,4) equation at different dates.
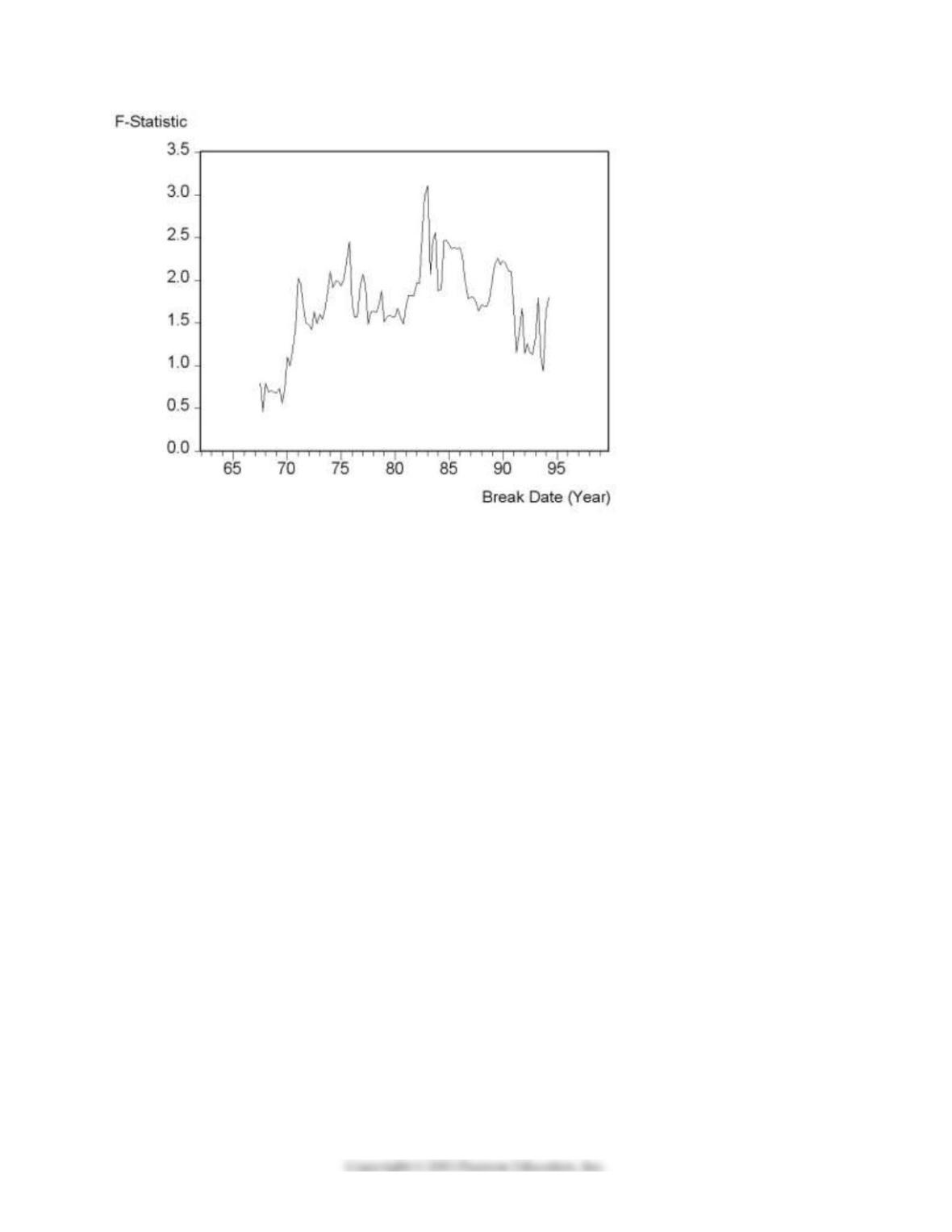
14
The QLR–statistic with 15% trimming is 3.11. Comment on the figure and test for the hypothesis of a
break in the ADL(4,4) regression.
(c) To test for the stability of the Canadian Phillips curve in the 1990s, you decide to perform a pseudo
out–of–sample forecasting. For the 24 quarters from 1994:I–1999:IV you use the ADL(4,4) model to
calculate the forecasted change in the inflation rate, the resulting forecasted inflation rate, and the forecast
error. The standard error of the ADL(4,4) for the estimation sample period 1962:1–1993:4 is 1.91 and the
sample RMSFE is 1.70. The average forecast error for the 24 inflation rates is 0.003 and the sample
standard deviation of the forecast errors is 0.82. Calculate the t–statistic and test the hypothesis that the
mean out–of–sample forecast error is zero. Comment on the result and the accompanying figure of the
actual and forecasted inflation rate.

16
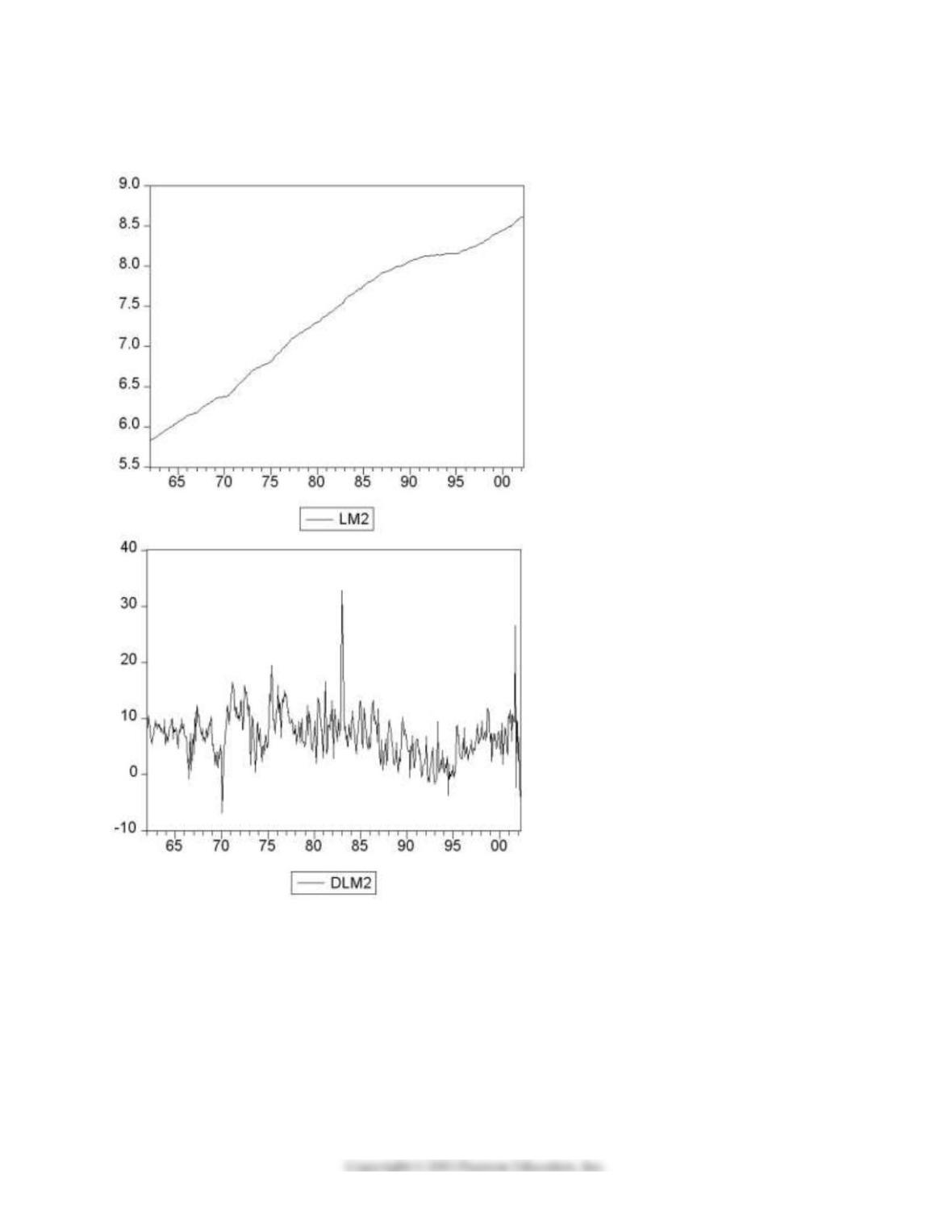
4) You collect monthly data on the money supply (M2) for the United States from 1962:1–2002:4 to forecast
future money supply behavior.
where LM2 and DLM2 are the log level and growth rate of M2.

(a) Using quarterly data, when analyzing inflation and unemployment in the United States, the textbook
converted log levels of variables into growth rates by differencing the log levels, and then multiplying
these by 400. Given that you have monthly data, how would you proceed here?
(b) How would you go about testing for a stochastic trend in LM2 and DLM2? Be specific about how to
decide the number of lags to be included and whether or not to include a deterministic trend in your test.
The textbook found the (quarterly) inflation rate to have a unit root. Does this have any affect on your
expectation about whether or not the (monthly) money growth rate should be stationary?
(c) You decide to conduct an ADF unit root test for LM2, DLM2, and the change in the growth rate
ΔDLM2. This results in the following t–statistic on the parameter of interest.
LM2
with trend
DLM2
without trend
DLM2
with trend
△
DLM2
without trend
–0.505
–4.100
–4.592
–8.897
Find the critical value at the 1%, 5%, and 10% level and decide which of the coefficients is significant.
What is the alternative hypothesis?
(d) In forecasting the money growth rate, you add lags of the monetary base growth rate (DLMB) to see if
you can improve on the forecasting performance of a chosen AR(10) model in DLM2. You perform a
Granger causality test on the 9 lags of DLMB and find a F–statistic of 2.31. Discuss the implications.
(e) Curious about the result in the previous question, you decide to estimate an ADL(10,10) for DLMB
and calculate the F–statistic for the Granger causality test on the 9 lag coefficients of DLM2. This turns out
to be 0.66. Discuss.
(f) Is there any a priori reason for you to be skeptical of the results? What other tests should you perform?

5) Having learned in macroeconomics that consumption depends on disposable income, you want to
determine whether or not disposable income helps predict future consumption. You collect data for the
sample period 1962:I to 1995:IV and plot the two variables.
(a) To determine whether or not past values of personal disposable income growth rates help to predict
consumption growth rates, you estimate the following relationship.
t = 1.695 + 0.126 ΔLnCt–1 + 0.153 ΔLnCt–2,
(0.484) (0.099) (0.103)
+ 0.294 ΔLnCt–3 – 0.008 ΔLnCt–4
(0.103) (0.102)
+ 0.088 ΔLnYt–1 – 0.031 ΔLnYt–2 – 0.050 ΔLnYt–3 – 0.091 ΔLnYt–4
(0.076) (0.078) (0.078) (0.074)
The Granger causality test for the exclusion on all four lags of the GDP growth rate is 0.98. Find the
critical value for the 1%, the 5%, and the 10% level from the relevant table and make a decision on
whether or not these additional variables Granger cause the change in the growth rate of consumption.
(b) You are somewhat surprised about the result in the previous question and wonder, how sensitive it is
with regard to the lag length in the ADL(p,q) model. As a result, you calculate BIC and AIC of p and q
from 0 to 6. The results are displayed in the accompanying table:
p,q
BIC
AIC
0
5.061
5.039
1
5.052
4.988
2
5.095
4.989
3
5.110
4.960
4
5.165
4.972
5
5.206
4.973
6
5.270
4.992
Which values for p and q should you choose?
(c) Estimating an ADL(1,1) model gives you a t–statistic of 1.28 on the coefficient of lagged disposable
income growth. What does the Granger causality test suggest about the inclusion of lagged income
growth as a predictor of consumption growth?

6) (Requires Internet Access for the test question)
The following question requires you to download data from the internet and to load it into a statistical
package such as STATA or EViews.
a. Your textbook estimates an AR(1) model (equation 14.7) for the change in the inflation rate using a
sample period 1962:I — 2004:IV. Go to the Stock and Watson companion website for the textbook and
download the data “Macroeconomic Data Used in Chapters 14 and 16.” Enter the data for consumer price
index, calculate the inflation rate, the acceleration of the inflation rate, and replicate the result on page 526
of your textbook. Make sure to use heteroskedasticity–robust standard error option for the estimation.
b. Next find a website with more recent data, such as the Federal Reserve Economic Data (FRED) site at
the Federal Reserve Bank of St. Louis. Locate the data for the CPI, which will be monthly, and convert the
data in quarterly averages. Then, using a sample from 1962:I — 2009:IV, re–estimate the above
specification and comment on the changes that have occurred.
c. Based on the BIC, how many lags should be included in the forecasting equation for the change in the
inflation rate? Use the new data set and sample period to answer the question.