
Chapter 18
Multivairate Data Analysis: Discriminant Analysis, Factor Analysis, Cluster
Analysis, and Multidimensional Scaling
between groups has the following problem(s):
a. It is difficult to anticipate all the graphs that might be useful.
b. Two dimensional graphs are limited in the information they convey.
c. When multiple variables are considered simultaneously, higher dimension graphs
(greater than two dimensions) become difficult to interpret.
d. Only a and b are involved.
e. All of the above are involved.
(Use the following information to answer the next two questions.)
A study was done in an attempt to discriminate between the listeners of three popular
AM radio stations during the morning “drive-time” period. The following
demographic variables were used in the analysis: age, income, education, marital
status, number of children at home, and gender. Use the information to answer the
following two questions?
a. 1
b. 2
c. 3
d. 4
e. None of the above.
how many different two-way graphs are possible?
a. 12
b. 15
c. 120
d. 16
e. None of the above.
variables in discriminating between groups?
a. the mean differences of the groups on each variable
b. the standardized discriminant coefficients
c. the discriminant loadings
d. b and c only
e. all of the above

ascertained by
a. squaring the value of the discriminant loading.
b. examining the standardized discriminant coefficient.
c. taking the square root of the discriminant loading.
d. squaring the mean discriminant score.
e. multiplying the discriminant loading by the mean value of the variable.
a. The “hit rate” in a confusion matrix indicates the proportion of sample units
correctly classified by the classification decision rule.
b. When attempting to assess the contribution of each variable to the discriminant
function one should use the raw score weights.
c. The cutting score is the score that divides the mean discriminant scores.
d. A confusion matrix is a two way table that contrasts actual group membership
with predicted group membership.
e. The mean discriminant score can be calculated by substituting the mean of each
variable in the derived discriminant function.
a. Discriminant analysis is useful in marketing for examining differences between
groups.
b. In discriminant analysis the dependent variable is a dichotomy or multichotomy,
whereas in regression it is typically interval scaled.
c. A two-group discriminant analysis can be transformed into a regression problem
simply by using a 0/1 dummy code for the dependent variable.
d. The degree of correlation among predictors is of concern in both discriminant and
regression analysis.
e. The criterion that is satisfied in solving for the discriminant function is the
maximization of the ratio of within-group variation to between-group variation.
importance of variables in discriminating between groups in discriminant analysis?
a. the mean differences of the groups on each variable
b. the discriminant coefficients
c. the pairwise correlations between the variable and the discriminant score
d. the standardized coefficients
e. Both b and c are not quantities used to assess the relative importance of variables
in discriminating between groups.
probably NOT appropriate?
a. the investigation of differences between light and heavy users of a product
b. the investigation of naturally occurring market segments existing in a market
c. the determination of the basic dimensions that underlie customer brand loyalty
d. the investigation of brand-loyal vs. non-brand-loyal customers
e. discriminant analysis is the most appropriate method of data analysis in each of
these situations

chance criterion is approximately
a. .36.
b. .48.
c. .52.
d. .58.
e. 1.40.
a. begin interpretation of the function by examining the discriminant coefficients
b. check the statistical significance of the function
c. standardize the discriminant coefficients
d. classify individuals using the discriminant function
e. none of the above
(Use the information below to answer the next three questions.)
In a five variable two group discriminant analysis, the following weights were derived:
V1 = .561, V2 = .030, V3 = .049, V4 = .701, V5 = -.021. The corresponding pooled
standard deviations are S1 = 4.60, S2 = 1.23, S3 = 10.40, S4 = 13.23, and S5 = 8.30.
For individual 1, the values for the four variables were X1 = 10, X2 = 3, X3 = 25, X4 =
36, and X5 = 42.
a. 26.98.
b. 27.65.
c. 3l.30.
d. 32.16.
e. 33.04.
a. 363.08.
b. 365.21.
c. 372.53.
d. 380.47.
e. 392.03.
a. X1
b. X2
c. X3
d. X4
e. X5

The mean discriminant score for group one is 28.4 while the mean discriminant score
for group two is 20.8. There are 20 managers in group one and 24 managers in group
two. What is the cutting score useful for classifying individuals into the two groups?
a. 24.9
b. 24.6
c. 24.3
d. 28.4
e. more information is needed
In a five group discriminant problem, where the groups are equal in size, the mean
discriminant score for each group is Y1 = 13.01, Y2 = 24.65, Y3 = 3.02, Y4 = 8.03, and Y5 =
42.06.
a. one
b. two
c. three
d. four
e. five
a. 18.83
b. 16.75
c. 19.02
d. 18.90
e. none of the above
analyst should focus most of his/her attention on the
a. individual column totals.
b. individual row totals.
c. both the individual column and row totals.
d. total number of subjects in the diagonal of the matrix.
e. average of the column totals.

(Use the following matrix to answer the next two questions.)
________________________________________________________
Actual Predicted Classification Total
Classification A B C
A 10 3 8 21
B 6 15 1 22
C 8 4 20 32
Total 24 22 29 75
________________________________________________________
a. .60.
b. .62.
c. .64.
d. .66.
e. .70.
a. .28.
b. .30.
c. .32.
d. .34.
e. .36.
chance criterion?
a. They are equal in value when the diagonal entries are the same.
b. They are equal in value when group sample sizes are equal.
c. The maximum chance criterion is always greater than the proportional chance
criterion.
d. The proportional chance criterion is always greater than the maximum chance
criterion.
e. None of the above are true.
a. divides the mean discriminant scores.
b. determines which discriminant functions are statistically significant.
c. determines which discriminant coefficients are statistically significant.
d. is used as a guide to classify subjects.
e. is a and d above.
a. indicates the proportion of sample units correctly classified.
b. is estimated by dividing the sum of the diagonal entries by the total number of
individuals in all groups.
c. can only be estimated when there are three or fewer groups.
d. is all of the above.
e. is a and b above.

a. substituting the mean of each variable in the desired discriminant function.
b. substituting the mean of each variable multiplied by the pooled variance.
c. taking the square root of the cutting score.
d. squaring the cutting score.
e. a and c above.
a. to indicate on which observed variables entities differ most.
b. to identify the dimensions that underlie constructs.
c. to summarize the important information in a set of variables by a new smaller set
of variables.
d. all of the above.
e. b and c above.
a. transform a set of interrelated variables into a set of unrelated linear combinations
of these variables.
b. choose the set of linear combinations so that each factor accounts for an
increasing proportion of the variance in the original variables.
c. choose the set of linear combinations so that the factors are uncorrelated with
each other.
d. a and b.
e. a and c.
a. the proportion of variation accounted for by the factor.
b. the proportion of variation in the variable accounted for by the complete set of
possible factors.
c. the proportion of variation shared by one pair of variables.
d. the proportion of variation in the variable shared by all variables in the analysis.
e. none of the above.
a. the proportions of variance in the variable accounted for by the factor
b. the correlations between the factors and the variables
c. the importance of the variables in the analysis
d. the achieved communality
e. the correlations between any two variables used in the analysis
solution, the researcher should
a. examine the size of the latent roots.
b. plot the size of the latent roots against the number of factors.
c. examine the amount of covariability recovery.
d. examine the amount of variability recovery.
e. all of the above.

a. maintain the right angles between the factors.
b. enhance the substantive interpretation of the unrotated factor solution.
c. force the entries in the columns of the factor loading matrix to be near 0 or 1.
d. all of the above.
e. a and b above.
neighborhood of
a. .20 to .25.
b. .25 to .30.
c. .30 to .35.
d. .35 to .40.
e. .40 to .45.
a. an improved substantive interpretation of the solution.
b. a change in the achieved communality estimate for any one variable.
c. a change in the proportion of variance accounted for by any one factor.
d. a and b above.
e. a and c above.
a. the communalities from an initial principal components model can be used.
b. the smallest absolute value of the correlation of the variable with any other
variable can be used.
c. the highest achieved communality from a principal components model can be
used.
d. a separate communality estimate is unnecessary because the classical factor model
simply uses 1’s in the diagonal.
e. a and c.
(Use the following table to answer the next 6 questions.)
Factor Loading Matrix
Variable Factor 1 Factor 2
inactivity .20 .70
aggressiveness .70 .10
ambition .80 .05
stress .60 .15
a. .04
b. .38
c. .13
d. 1.53
e. .51

a. 1.53.
b. .04.
c. .53.
d. .51.
a. .19.
b. .18.
c. .88.
d. .05.
e. .44.
solution?
a. 51%
b. 100%
c. 78%
d. 27%
e. more information is needed
a. inactivity and aggressiveness
b. inactivity and ambition
c. aggressiveness and stress
d. aggressiveness and ambition
e. stress and ambition
a. inactivity
b. aggressiveness
c. ambition
d. stress
e. a and c
that can be extracted is
a. one.
b. two.
c. three.
d. four.
e. none of the above.
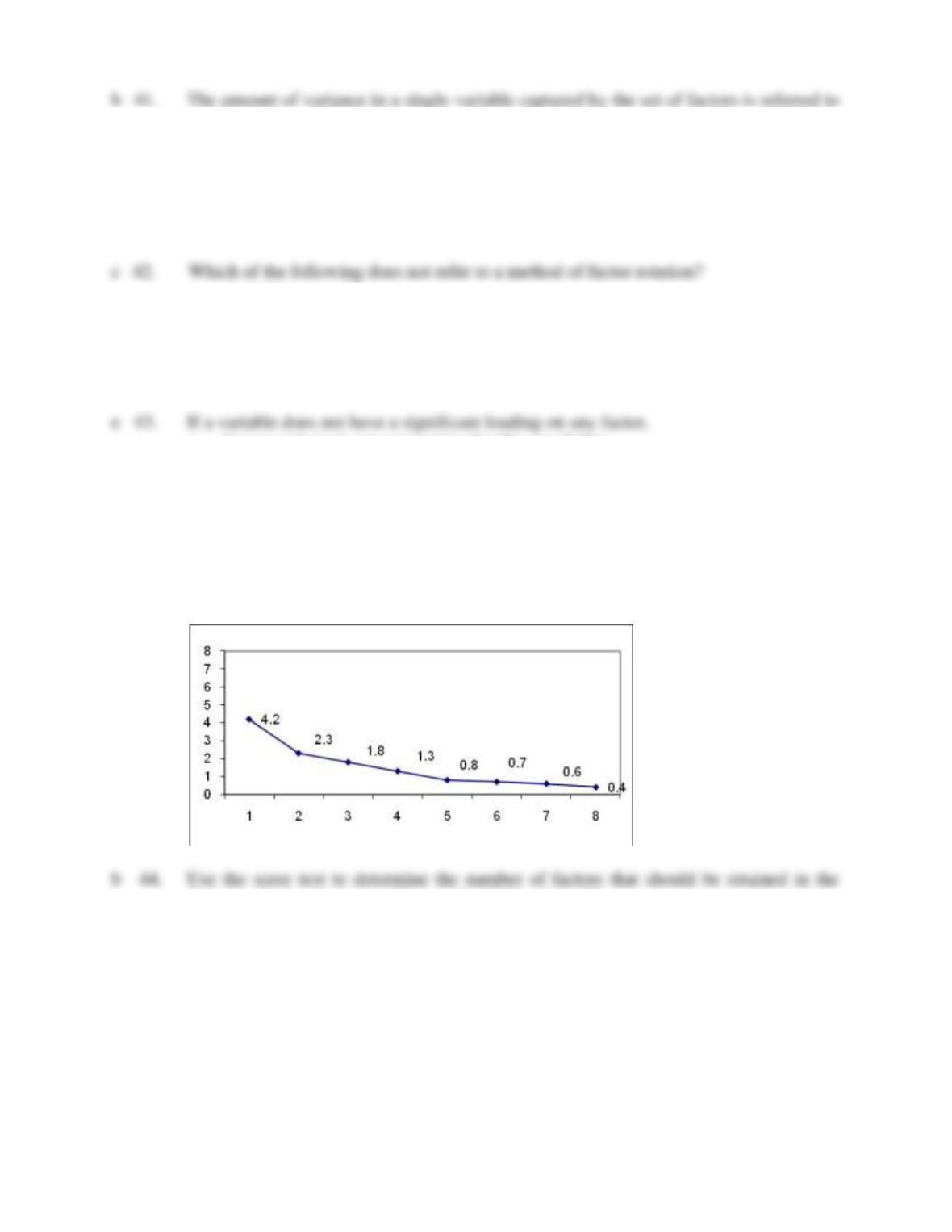
as the
a. factor loading.
b. achieved communality.
c. variability recovery of a single factor.
d. covariability recovery.
e. latent root.
a. varimax
b. oblique
c. epsilon
d. orthogonal
e. quartimax
a. factor analysis is not appropriate for this set of data.
b. the analyst may decide to eliminate the variable if it is not important to the study’s
object.
c. the variable should be eliminated if its achieved communality is low.
d. all of the above are correct.
e. b and c above are correct.
(Use the following information for the next three questions.)
factor analysis. How many factors should be retained?
a. 1
b. 2
c. 3
d. 4
e. 5

retained in the factor analysis. How many factors should be retained?
a. 1
b. 2
c. 3
d. 4
e. 5
number of variables on which this principal components factor analysis can be based?
a. 2
b. 8
c. 16
d. 4
e. more information is needed
a. the pattern of correlations is high throughout the correlation matrix.
b. the slot of the latent roots indicates no sharp break.
c. covariability recovery is high.
d. no dependent variable is present in the data.
e. there are more than 10 variables to be analyzed.
a. purify original sets of scale items.
b. develop customer profiles.
c. determine key preference attributes.
d. assess a company’s image.
e. all of the above.
analyzing data?
a. What is the dependent variable?
b. Should factor analysis be applied to the data?
c. Which factor model should be used?
d. Should the initial solution be rotated?
e. All of the above are key decisions that need to be made when factor analyzing
data.
analyzing data?
a. selecting and coding the attributes necessary to generate natural groupings
b. selecting an appropriate method of measuring the similarity or resemblance of the
objects
c. select a method of testing the significance of the solution and naming the resulting
clusters
d. both a and c are not key decision in cluster analysis
e. all of the above are key decisions in cluster analysis

Answer the next three questions referring to the following diagram. The numbers refer to the
measure of similarity between object A and the other objects, B, C, and D.
would be allowed to join cluster BCD is
a. .617.
b. .484.
c. .372.
d. .491.
e. .428.
would be allowed to join cluster BCD is:
a. .617.
b. .484.
c. .372.
d. .491.
e. .428.
would be allowed to join cluster BCD is
a. .617.
b. .484.
c. .372.
d. .491.
e. .428.
a. plot the number of clusters against the fusion coefficient.
b. examine the standardized cluster scores.
c. determine the amount of variance explained by each cluster.
d. plot the number of clusters against the number of objects.
e. examine the cluster loadings.
A
D
C
B
.372
.484
.617

a. Different methods of cluster analysis can produce different results.
b. There is consensus on which method of cluster analysis is best under all
circumstances.
c. Nodal methods of factor analysis involve the selection of an object or objects to
serve as focal points for the clusters.
d. The average linkage method works better than the other hierarchical method of
cluster analysis.
e. Cluster analysis seeks to identify natural groupings of objects given the
multivariate nature of the data.
correlation, or distance matrix, that is, are the individual clusters sufficiently
homogeneous and is the system as a whole consistent with the input similarities, the
following procedure(s) can be performed:
a. the variables used to determine the clusters can be tested to determine if the
clusters have statistically different values across the groups.
b. the reliability of the estimates can be assessed by splitting the data into multiple
subsets and assessing whether the same clusters are produced when the subsets
are analyzed.
c. significance tests can be performed that compare the clusters on variables not
used to generate the solution.
d. All of the above procedures are correct.
e. Both b and c are correct.
a. Linkage methods are hierarchical clustering techniques.
b. The dendrogram is used to capture the hierarchical clustering of objects.
c. A prime node is the most atypical object around which all remaining objects are
clustered.
d. All clustering procedures are based on some measure of similarity between
objects.
e. Standardization of the variables is recommended in most instances.
markets for a new product. He has identified two cities that he feels represent the two
procedures. A total of ten cities will be used. Which method of cluster analysis should
the researcher use?
a. single linkage method
b. nodal method
c. factor analysis method
d. complete linkage method
e. either a or d should be used

to initially partition the set of objects?
a. polar nodal method
b. prime nodal method
c. picking specific objects to serve as group centroids
d. randomly assigning objects to one of a prespecified number of clusters
e. all of the above
a. grouping customers according to product benefits
b. determining the underlying dimensions of customer satisfaction
c. sorting household demand patterns into similar shapes
d. determining spheres of opinion leadership
e. assessing the similarity of world markets
a. dichotomous.
b. multichotomous.
c. interval scaled.
d. ratio scaled.
e. all of the above.
number of clusters versus the fusion coefficient, the analyst should look for
a. significant savings in the fusion coefficient.
b. points where the curve approaches the y axis.
c. points where the curve flattens out.
d. points where the line begins to approach the x axis.
e. both a and c.
The following questions focus on Multidimensional Scaling:
a. plot m stimuli in m-1 space.
b. plot m stimuli in two-dimensional space.
c. determine an arbitrary configuration of points in space which have a nice
geometrical shape.
d. determine how a multidimensional configuration can be captured by a
numerical score.
e. characterize people’s perceptions of the similarity of objects and their
preferences among objects in a multidimensional space.
which of the following?
a. the number of dimensions underlying the respondent’s judgments.
b. a map of the configuration characterizing the respondent’s judgments.
c. attributes the individual is using when making judgments.
d. a and b above.
e. all of the above.

a. Perceptual maps can be created using attribute-based or nonattribute-based
approaches.
b. Multidimensional scaling analysis is typically used to refer to the attribute-
based approaches to creating perceptual maps.
c. The attribute-based approaches for developing perceptual maps rely on
characteristic-by-characteristic assessments of the various objects using, for
example, Likert-type scales.
d. a and b.
e. a, b, and c.
a. The attribute-based approaches for developing perceptual maps require
subjects to make overall judgments about the similarity of various objects
using whatever attributes they wish.
b. The emphasis in multidimensional scaling analysis is to determine the
maximum dimensionality needed to capture adequately a person’s perceptual
or preference judgments.
c. The idea of distance or more formally psychological nearness or proximity is
one of the key ideas in multidimensional scaling.
d. One of the key outputs of a multidimensional scaling analysis is the computer’s
identification of the attributes underlying an individual’s similarity judgments.
e. They are all false.
a. the mapping of perceptions and preferences.
b. the spatial relationship of objective data.
c. the mapping and transformation of distances.
d. the evaluation of the positive and negative aspects of an object.
e. the mapping of a unidimensional concept in space.
The methods for doing this include
a. computing the correlations between physical characteristics and the scores of
the various dimensions of the configuration.
b. naming them on the basis of the researcher’s insight and experience.
c. locating the ideal points.
d. increasing the number of dimensions.
e. a and b.

a. Perceptual maps can only be generated when respondents provide direct
judgments about the similarity of various objects, e.g., A is more similar to C
than it is to B.
b. One encouraging empirical finding regarding the development of perceptual
maps is that the dimensions do not seem to depend upon the objects included
in the stimulus set used to secure the judgments.
c. The greater the number of dimensions used with a perceptual map in
multidimensional scaling, the better the fit of objects within the perceptual
map.
d. a and c.
e. b and c.
a. In multidimensional scaling, it is easier to work with larger numbers of
dimensions in a perceptual map for purposes of interpretation.
b. By varying the number of dimensions used with a multidimensional scaling
analysis, it is always possible to obtain a perfect fit of all objects in a
perceptual map.
c. It is not possible to obtain perfect fit of all objects in a multidimensional
scaling analysis with just two dimensions.
d. a and b.
e. a, b, and c.
a. metric output from metric input.
b. rank order output from ordinal input.
c. nominal output from ordinal input.
d. metric output from nominal input.
e. metric output from ordinal input.
a. An advantage of the nonattribute-based approaches over the attribute-based
approaches in the development of perceptual maps is that they make naming
the dimensions easier.
b. The attribute-based approaches to the development of perceptual maps require
a relatively more accurate and complete set of attributes to be specified in
advance of data collection.
c. Computer programs for the attribute-based approaches to the development of
perceptual maps are more readily available and less expensive to run than are
the programs for the nonattribute-based approaches.
d. The attribute rating approaches to multidimensional scaling analysis make it
easier in comparison to direct methods to cluster respondents into groups with
similar perceptions.
e. The attribute and nonattribute approaches to perceptual mapping can produce
very different maps.

has ranked a group of objects according to similarity?
a. What does the configuration of objects look like when all are considered
simultaneously?
b. What attributes is the individual using in making his or her judgments?
c. Which objects were considered earliest in the ranking process by the
respondent?
d. How many dimensions underlie this respondent’s judgments of similarity?
e. All of the above are typically of concern.
multidimensional scaling?
a. After subjects have evaluated objects in terms of defined attributes, the
researcher can correlate the attribute scale scores for each object with the
coordinates for each object in the perceptual map.
b. Managers may use their experience to interpret the dimensions.
c. Researchers may attempt to relate the dimensions to actual attributes of the
objects under study.
d. Researchers may name the resulting dimensions based on a priori hypotheses.
e. All of the above are methods for naming dimensions in MDS.
a. is an index of variation.
b. is a measure of central tendency.
c. is a lack of fit index.
d. is an index of reproducibility.
e. is an index of dispersion.
a. Perceptual maps cannot only be produced when direct judgments about the
similarity of objects are obtained, but also when the same objects are rated on a
predefined set of attributes.
b. Similarity measurement has an advantage over attribute ratings in that it allows
respondents to employ only those dimensions they normally use in making
judgments among objects.
c. The attribute rating approach to multidimensional scaling analysis facilitates
naming the dimensions.
d. Similarity measurement has the advantage over attribute ratings in
multi-dimensional scaling analysis in that it better handles the problem of
grouping respondents with similar perceptions.
e. Similarity judgments can be gathered both directly and by having respondents
rate objects on a predefined set of attributes.

a. An ideal point is a hypothetical point on a multidimensional scaling perceptual
map that possesses the perfect combination of attributes or dimensions.
b. The first decision an analyst must make in a multidimensional scaling analysis
regards the choice of objects, products, or brands to be used in the analysis.
c. When selecting products or brands for use in a multidimensional scaling
analysis, an important trade-off occurs between the desire to include enough
brands so that all important dimensions will be represented and the desire to
keep the number of respondents needed for the analysis to a minimum.
d. a and b.
e. a, b, and c.
approaches to the development of perceptual maps is FALSE?
a. The attribute-based approaches rely on characteristic-by-characteristic
assessments of the various objects.
b. The nonattribute methods ask respondents to judge directly how similar the
various alternatives are using whatever criteria they desire.
c. The attribute-based approaches make naming the dimensions easier.
d. Computer programs for the attribute-brand approaches are more readily
available and less expensive to run.
e. Computer programs for the attribute-based approaches are more expensive to
run.
appropriate?
a. determining viable segments that exist in a market
b. finding “holes” in a market that might support a new product venture
c. identifying the combination of attributes buyers most prefer
d. determining salient product attributes perceived by buyers in a market
e. MDS is appropriate for each of these applications
scaling procedures are determined by
a. the research organization conducting the research.
b. the stimulus set.
c. the researcher.
d. the company sponsoring the research project.
e. the statistical program itself.
multidimensional scaling analysis?
a. deciding how to name the resulting dimensions
b. the number of respondents to use in the analysis
c. method of securing similarity judgments
d. choosing which products or brands to use in the analysis
e. All of the above are considered key decisions.
into all of the following EXCEPT
a. the combination of attributes preferred by buyers.
b. the viable segments that exist in a market.
c. buyer’s attitudes toward a product.
d. possible unexploited market niches.
e. salient product attributes perceived by buyers in the market.
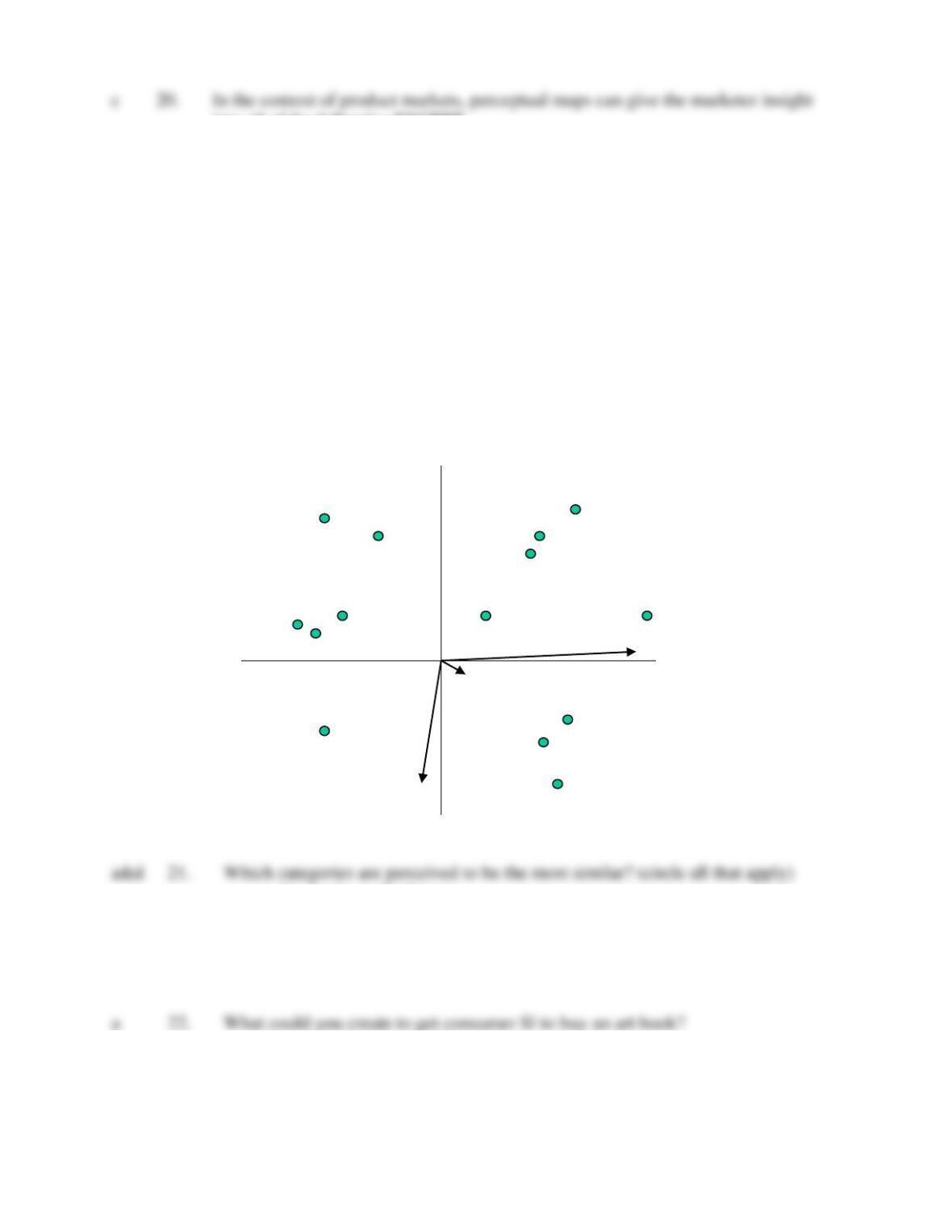
Use the following perceptual map to answer the next 4 questions.
Consumers browsing in your local bookstores were asked to make judgments of similarity
among various genre of books. The consumers also made ratings of attributes of the types of
books, so that vectors representing those attributes might be plotted in the space, aiding
interpretation of the dimensions. The consumers also indicated their preferences among these
categories. The results are plotted below.
a. biography and reference
b. adventure and espionage
c. biography, reference, and self-help
d. literature and romance
e. literature and poetry
a. photos of the Rocky Mountains
b. masculine art
c. an art audiobook
d. art that combined fiction and masculinity
e. nothing; S1 is not into art books
dim.II
art books
poetry
spiritual
literature
S3
romance
S2
self-help
humor
biography
mysteries
reference
S5
fiction
dim.I
S4
audiobooks
true crime
adventure
espionage
S1
westerns
male-dominated
purchases

a. a woman; she likes poetry and literature
b. a man; he’s close to dimension 2
c. a woman; she’s opposite the “male” vector
d. a man; but he happens to like poetry
e. indeterminate
being near the origin?
a. S5 likes all kinds of books
b. S5 really doesn’t like any genre of books
c. S5 really likes audiobooks
d. S5 likes fiction and nonfiction equally well
e. all of these might account for the location of S5